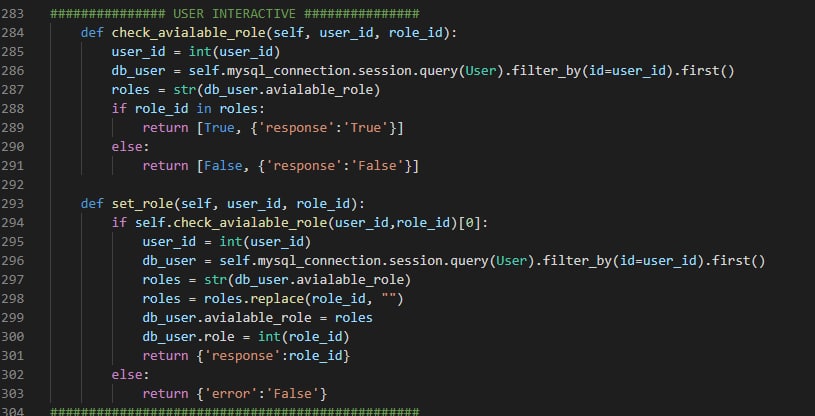
что может быть очень сложно, потому что с нормальными названиями переменных иногда приходит осознание, что весь алгоритм нелогичный и надо переписывать
Народ, посдкажите по lxml. Есть страничка в которой инфа лежит в div class и в параграфах внутри класса <p>text1<p/> <p>text2<p/> <p><p/> <p>text4<p/> Мне надо эти text выбрать. Делаю cdt = cheques_details_tree.xpath(".//div[@class='section']//p//text()") Но при этом в выборку не попадают пустые значения из <p><p/> И нумерация значений в полученном списке слетает. Как это исправить?