



АМ
Size: a a a
2019 October 08
НК
Большое спасибо. Че-та я как-будто неправильные курсы по питону смотрел 😄
АМ
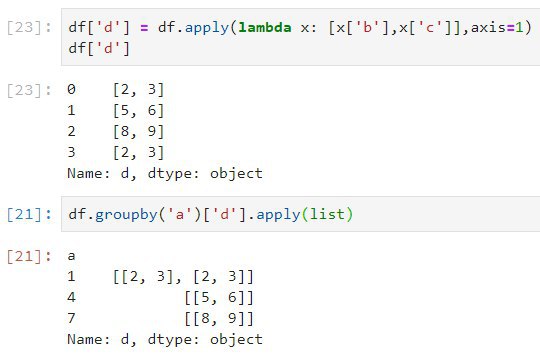
Ну это такие достаточно низкоуровневые хаки pandas. Их мало где системно освещают(
e
Результаты опроса разработчиков от jeybrains (в целом и с разделением по языкам) - интересно) посмотрите в целом и потом ткните в python)
https://www.jetbrains.com/lp/devecosystem-2019/
https://www.jetbrains.com/lp/devecosystem-2019/

DP
Подскажите,
Есть список из 2000 абзацев русского текста. Как их по смыслу разнести по 10 категориям? То есть на выходе, чтобы напротив каждого абзаца был балл от 1 до 10.
Интересуют простые способы, чтобы потом погрузится в тему. А то столько разных библиотек, непонятно с чего начать.
Есть список из 2000 абзацев русского текста. Как их по смыслу разнести по 10 категориям? То есть на выходе, чтобы напротив каждого абзаца был балл от 1 до 10.
Интересуют простые способы, чтобы потом погрузится в тему. А то столько разных библиотек, непонятно с чего начать.
АМ
Из самого простого: сначала для каждого абзаца сформировать вектор с помощью tf-idf vectorizer, а потом k-means. Вот пример тетрадки: https://www.kaggle.com/jbencina/clustering-documents-with-tfidf-and-kmeans

ВЛ

Какой же пандас логичный))
DP
Из самого простого: сначала для каждого абзаца сформировать вектор с помощью tf-idf vectorizer, а потом k-means. Вот пример тетрадки: https://www.kaggle.com/jbencina/clustering-documents-with-tfidf-and-kmeans
Спасибо! А он русский текст поддерживает? Извините, что у вас, а не у гугла спрашиваю.
VN
Привет!
А не подскажите, какой-нибудь гайд по стримингу данных из ГА в BQ?
А не подскажите, какой-нибудь гайд по стримингу данных из ГА в BQ?
VN
https://web-analytics.me/streaming_in_bigquery
Находил вот это, но тут как я понял все данные из ГА кидаются в BQ, а мб можно как-то отфильтровать, что нужно?
Находил вот это, но тут как я понял все данные из ГА кидаются в BQ, а мб можно как-то отфильтровать, что нужно?

АМ
Спасибо! А он русский текст поддерживает? Извините, что у вас, а не у гугла спрашиваю.
Tf-idf - это просто алгоритм. Он с любыми текстами работает. Другое дело, что качество кластеризации у вас будет выше если вы сначала произведёте лемматизацию текста. Для этого можно использовать pymystem
ВЛ
или вок2век
АМ
или вок2век
word2vec?
ВЛ
написал криво
МЧ
Подскажите,
Есть список из 2000 абзацев русского текста. Как их по смыслу разнести по 10 категориям? То есть на выходе, чтобы напротив каждого абзаца был балл от 1 до 10.
Интересуют простые способы, чтобы потом погрузится в тему. А то столько разных библиотек, непонятно с чего начать.
Есть список из 2000 абзацев русского текста. Как их по смыслу разнести по 10 категориям? То есть на выходе, чтобы напротив каждого абзаца был балл от 1 до 10.
Интересуют простые способы, чтобы потом погрузится в тему. А то столько разных библиотек, непонятно с чего начать.
Решала недавно похожую задачу, делала как @ax_makarov описал сейчас, только еще добавила биграммы. Сама бэендер, ДС задачу решала случайно, но ее приняли.
АМ
Ну да, его можно использовать вместо tf-idf для того, чтобы текст к вектору привести. Только тогда нужно взять для каждого слова из фразы вектор из word2vec и все их усреднить. Более правильный подход взять что-то вроде seq2vec или doc2vec
АМ
А вообще если продолжать дальше, то чатик начнёт превращаться в чатик по DS. Мне бы этого не хотелось))
ВЛ
А вообще если продолжать дальше, то чатик начнёт превращаться в чатик по DS. Мне бы этого не хотелось))
а там про железо слишком много говорят))
N
Есть кто плотно с апи серч консоли работает?