



ЯК
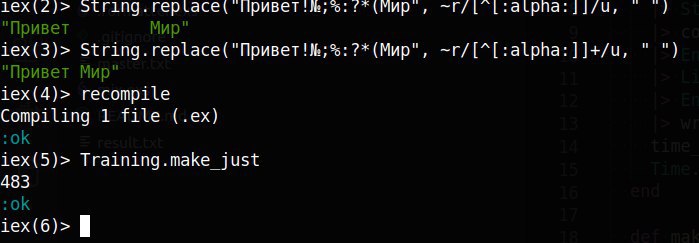
Выкини плюс в регулярке и проверь еще раз

Ну в плане результат на малой строке, что это изменит на большой?
Size: a a a
ЯК
ЯК
ЯК
ЯК
ŹR
ЯК
ŹR
ЯК
LL
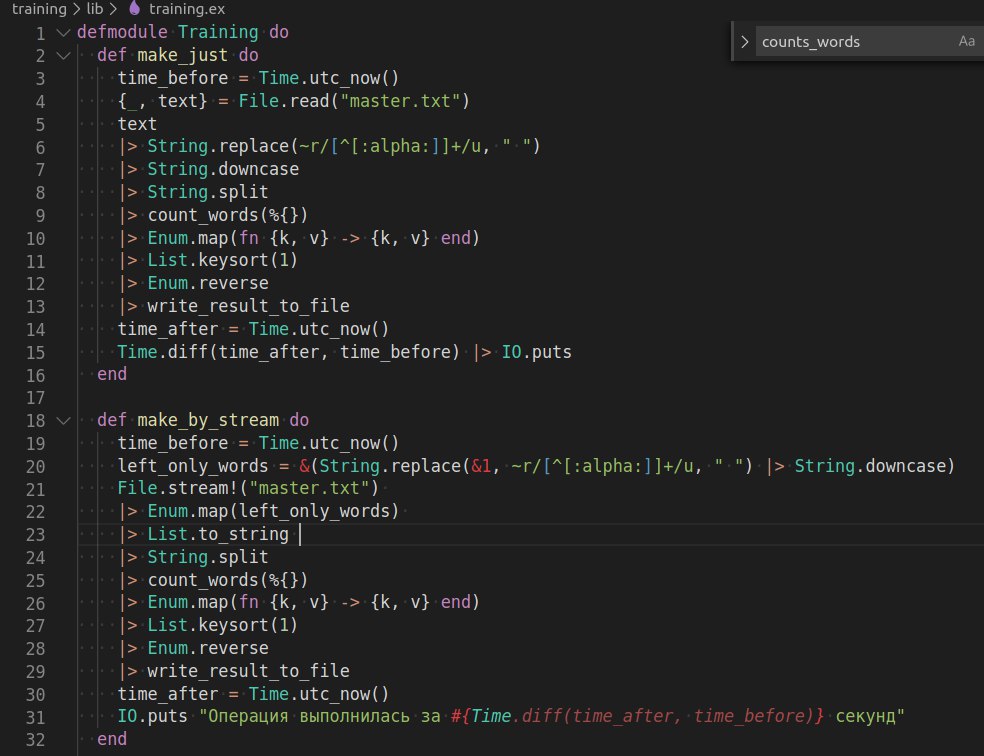
Enum.map(fn {x, y} -> {x, y} end) ?!PG
Enum.map(& &1)LL
LL
Enum.map(& &1)ЯК
Enum.map(fn {x, y} -> {x, y} end) ?!LL
Map.to_list, а во вторых этот код можно переписать в один Enum.reduce и один Enum.sortŹR
ŹR
ЯК
ЯК
ЯК
LL