Задачка: сотрудникофикатор
Время для задачки! Допустим, вы основали модный HR-стартап, который подбирает идеальные коллективы сотрудников. Дело это нелёгкое, так что начали с простой эвристики:
> Любой коллектив идеален, пока в нём не появляется Френк
Подготовили интеллектуальный алгоритм, который предлагает сотрудника:
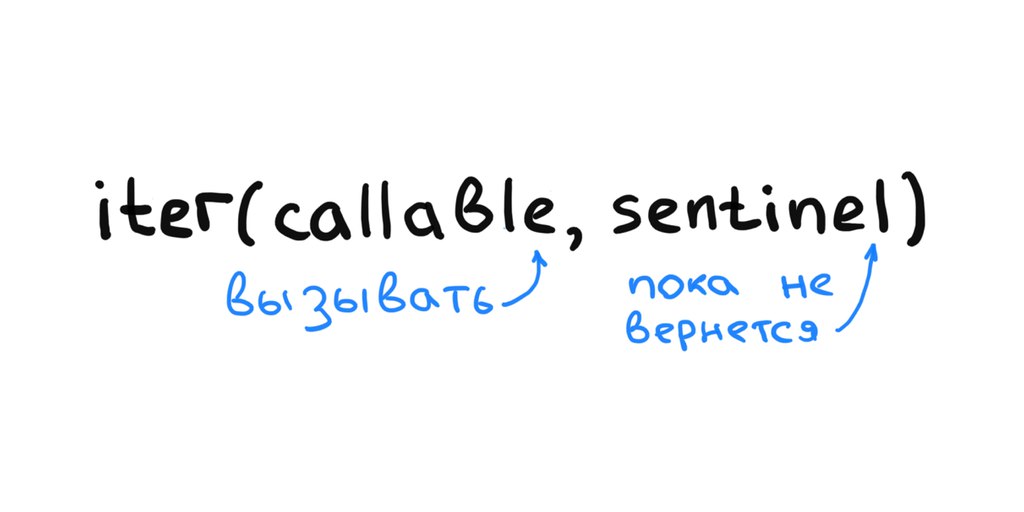
Остался последний шаг — разработать нечто под названием
Ваша задача — реализовать
Давайте я для затравки начну заведомо неудачным вариантом:
Ссылка на репл
Форкайте, реализуйте свой
Завтра вечером покажу лучшие варианты, а потом разберём плюсы и минусы каждого.
Время для задачки! Допустим, вы основали модный HR-стартап, который подбирает идеальные коллективы сотрудников. Дело это нелёгкое, так что начали с простой эвристики:
> Любой коллектив идеален, пока в нём не появляется Френк
Подготовили интеллектуальный алгоритм, который предлагает сотрудника:
import random
names = ["Френк", "Клер", "Зоя", "Питер", "Лукас"]
def employee():
name = random.choice(names)
return name
Остался последний шаг — разработать нечто под названием
employeficator(), что и будет подбирать дружный коллектив. Использоваться оно будет так:>>> [name for name in employeficator()]
['Зоя', 'Зоя', 'Питер']
>>> [name for name in employeficator()]
['Лукас', 'Зоя', 'Питер']
Ваша задача — реализовать
employeficator() максимально идиоматично.Давайте я для затравки начну заведомо неудачным вариантом:
def employeficator():
employees = []
name = employee()
while name != "Френк":
employees.append(name)
name = employee()
return employees
Ссылка на репл
Форкайте, реализуйте свой
employeficator() и присылайте ссылку на форк мне → @nalgeonЗавтра вечером покажу лучшие варианты, а потом разберём плюсы и минусы каждого.