ПЧ
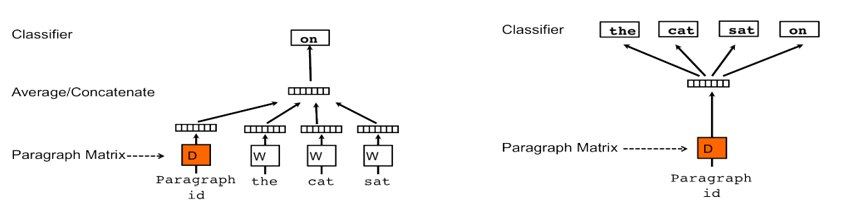
Здравствуйте. Я знаю, что w2v модели можно использоваться для оценки того, насколько слова "близки" по смыслу, но тут у меня возникает вопрос: можно ли обученные w2v модели использоваться для того, что бы оценить, насколько "слово" соответствует смысле текста?
К примеру мы подаём на вход текст рассказывающий о джинсах, и подаём отдельно слово "брюки". В теории хотелось бы увидеть связь между словом "брюки" и текстом о джинсах, даже если в тексте не упоминается это слово, ведь речь всё равно идёт об одежде. Ну естественно что у слова "брюки" должна быть похожесть на текст выше, чем у слова "торт"
К примеру мы подаём на вход текст рассказывающий о джинсах, и подаём отдельно слово "брюки". В теории хотелось бы увидеть связь между словом "брюки" и текстом о джинсах, даже если в тексте не упоминается это слово, ведь речь всё равно идёт об одежде. Ну естественно что у слова "брюки" должна быть похожесть на текст выше, чем у слова "торт"