



SМ
Size: a a a
2021 February 05
SМ
Вроде да
A
BiDAF, кажется так зовется, пробовали?
Не пробовали, так как для обучения используются примеры фраз для каждого intent (+ туда же отправляется разметка для задачи ner).
Спасибо, подумаем, как можно добавить ответ на вопрос в обучающую выбобрку (не всегда очевидно, так как пользователь может захотеть просто прервать диалог), чтобы затем применить BiDAF.
Спасибо, подумаем, как можно добавить ответ на вопрос в обучающую выбобрку (не всегда очевидно, так как пользователь может захотеть просто прервать диалог), чтобы затем применить BiDAF.
SP
Eug
Вы полагаете, использование эмбеддингов предложений что-то даст?
Здесь ведь требуется понимание смысла, который в эмбеддингах присутствует, но, как вы и написали, "в больших кавычках".
Насколько они "чувствительны" к вариантам "надо", "не надо", "возможно"?
В любом случае, спасибо за комментарий. Посмотрю Natasha и Yargy.
Здесь ведь требуется понимание смысла, который в эмбеддингах присутствует, но, как вы и написали, "в больших кавычках".
Насколько они "чувствительны" к вариантам "надо", "не надо", "возможно"?
В любом случае, спасибо за комментарий. Посмотрю Natasha и Yargy.
«Что-то» само собой даст, особенно если веса сдвинуть в эту сторону. Очень сильно зависит от того, какой подход примете - можете взять готовые модели для русского языка от hugging face зафайнтюнить и посмотреть на результаты.
SМ
Не пробовали, так как для обучения используются примеры фраз для каждого intent (+ туда же отправляется разметка для задачи ner).
Спасибо, подумаем, как можно добавить ответ на вопрос в обучающую выбобрку (не всегда очевидно, так как пользователь может захотеть просто прервать диалог), чтобы затем применить BiDAF.
Спасибо, подумаем, как можно добавить ответ на вопрос в обучающую выбобрку (не всегда очевидно, так как пользователь может захотеть просто прервать диалог), чтобы затем применить BiDAF.
Ну если прервался можно спец токеном западить или пустой строкой
A
Есть ли метод (или параметр) для токенизатора BERT (от deeppavlov на HuggingFace) не разбивать конкретное слово (список слов) на несколько токенов?
Может применение специальных токенов до и после слова?
Необходимо для получения вектора для конкретного слова.
Может применение специальных токенов до и после слова?
Необходимо для получения вектора для конкретного слова.
AK
Есть ли метод (или параметр) для токенизатора BERT (от deeppavlov на HuggingFace) не разбивать конкретное слово (список слов) на несколько токенов?
Может применение специальных токенов до и после слова?
Необходимо для получения вектора для конкретного слова.
Может применение специальных токенов до и после слова?
Необходимо для получения вектора для конкретного слова.
Эт так не работает. Работает подругому: БЕРТ бьет неизвестное слово на токены, обрабатывает токены, берем вектор первого токена, считаем его вектором всего слова. Или берем вектор последнего токена или считаем среднее векторов токенов слова
A
Эт так не работает. Работает подругому: БЕРТ бьет неизвестное слово на токены, обрабатывает токены, берем вектор первого токена, считаем его вектором всего слова. Или берем вектор последнего токена или считаем среднее векторов токенов слова
Слово ему известно - если оно в нормальной форме. Стоит только изменить окончание или написать с заглавной буквы - делит на два токена.
DD
Эт так не работает. Работает подругому: БЕРТ бьет неизвестное слово на токены, обрабатывает токены, берем вектор первого токена, считаем его вектором всего слова. Или берем вектор последнего токена или считаем среднее векторов токенов слова
Ещё можно добавить в словарь токенизатора новое слово, добавить в матрицу эмбеддингов соответствующий индекс для этого слова, и пофайнтюнить модель (предпочтительно заморозив все слои, кроме эмбеддингов) на текстах, где это слово встречается. На гитхабе huggingface этот пример обсуждается.
Но вариант Александра проще :)
Но вариант Александра проще :)
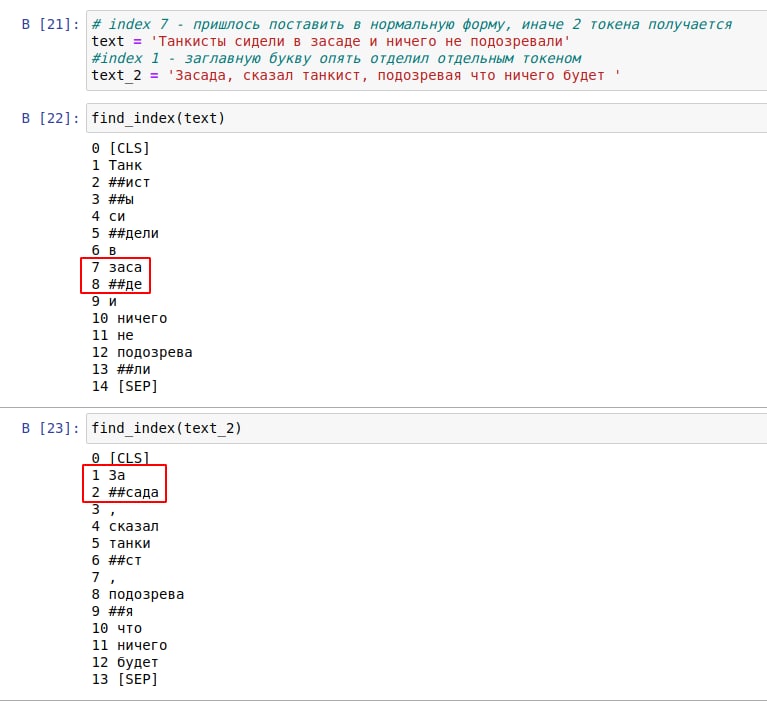
A
А сравнивать я буду в итоге с вектором слова, которое будет 100% в нормальной форме.
Попробую сложить (или среднее взять).
Попробую сложить (или среднее взять).
A
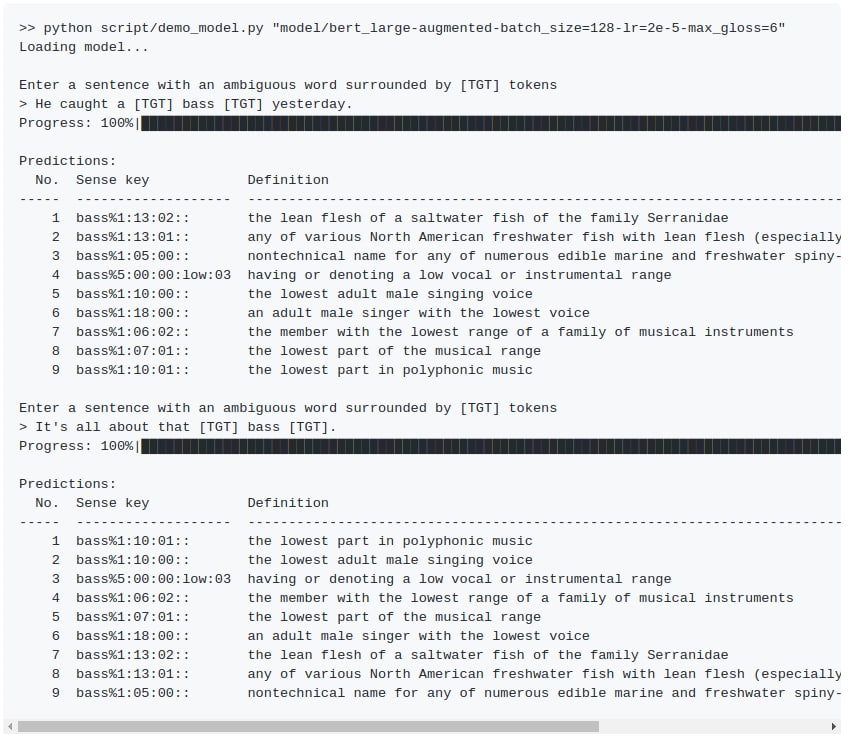
вот такой пример ещё попался...
A

Наверное можно вот сюда передавать список искомого слова.
AL
Нет, этот список будет влиять только на претокенизацию (которая делается до разделения слов на subword токены)
AL
По сути, если вашего токена нет в словаре сабвордов, то у него не будет id, и соответственно его не будет в таблице входных эмбеддингов
AL
С предобученными моделями - только усреднение выходных эмбеддингов, только хардкор
A
Пока буду просто ставить его в нормальную форму. А там уже если гипотеза будет работать, то наверное пойду в хардкор )))
AL
Пока буду просто ставить его в нормальную форму. А там уже если гипотеза будет работать, то наверное пойду в хардкор )))
Для удобства можно подавать токенайзеру список токенов вместо строки, см.
И потом получить индексы исходных слов для каждого сабворда:
is_split_into_words=True https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.__call__И потом получить индексы исходных слов для каждого сабворда:
tokenized_inputs = tokenizer(['mylongtoken', 'and', 'friends'], is_split_into_words=True)
for i, input_ids in enumerate(tokenized_inputs['input_ids']):
original_word_ids = tokenized_inputs.word_ids(i)
AK
Новые соревнования на Диалоге http://www.dialog-21.ru/evaluation/. Датасеты на русском языке на вес золота.
- seq2seq сложное предложение -> простое, симплификация
- Генерация заголовка для кластера новостей
- Нормализация именованных сущностей
- seq2seq сложное предложение -> простое, симплификация
- Генерация заголовка для кластера новостей
- Нормализация именованных сущностей
AK
Напрягает, что часто новые сообщения в закрепе?
Анонимный опрос
Проголосовало: 63