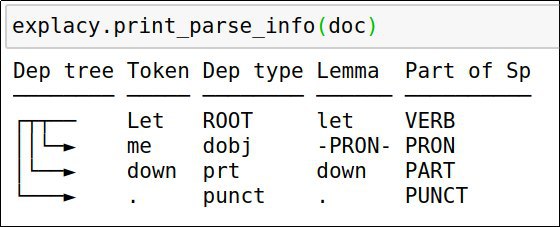
A
Всем привет! Такой вопрос. Есть у меня тексты (разговор абонента с оператором, без пунктуации, на английском) и в этих текстах в ручную выделены фразы нескольких категорий обещаний которые дал оператор абоненту (перезвонить назад, назначить встречу и т.д.). В целом 12 категорий. Сейчас я думаю над созданием алгоритма для этого. Выделил для себя два шага.
1) На первом шаге надо научить алгоритм находить конец и начало всех обещаний. То есть чтобы вставлялся тег начала и тег конца.
2) Второй шаг состоит в созданий классификатора, который бы распихивал обещания по нужным категориям.
Второй шаг, как я понимаю, хорошо разработан и это называется text classification. Сейчас смотрю как люди это делают. А вот по теме первого шага я чего-то не смог найти никаких разработок. Не подскажите в какую сторону копать? Может существуют подходы которые решают два шага одновременно?
1) На первом шаге надо научить алгоритм находить конец и начало всех обещаний. То есть чтобы вставлялся тег начала и тег конца.
2) Второй шаг состоит в созданий классификатора, который бы распихивал обещания по нужным категориям.
Второй шаг, как я понимаю, хорошо разработан и это называется text classification. Сейчас смотрю как люди это делают. А вот по теме первого шага я чего-то не смог найти никаких разработок. Не подскажите в какую сторону копать? Может существуют подходы которые решают два шага одновременно?