а на этой карте уже с домами, особенно это интересно видно в районе Планерной - там практически каждый дом одобрительной меткой помечен.
Что с историей:
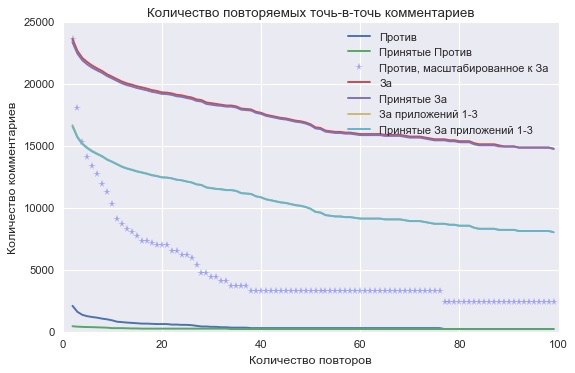
1) история не доведена до конца из-за того, что не смог распарсить оценочно 20-30% комментариев из pdf-ки и потому никуда не пошла
2) ПЗЗ приняли, критичность мб и отпала, но довести её, конечно, надо. Оценочная аналитика намекает на вбросы
3) я делал её итеративно, что позволило подобную карту иметь уже через дня 3 после начала и последовательно обновляя её, но из-за этого страдает точность на каждом этапе (в частности, классификация этих обращений): сделал каждый этап, но шлифовать я собирался после того, как доделаю фундамент - распарсить pdf
4) не пытался привлечь ещё народ - мой косяк, для дела нужно было привлекать дополнительных людей. Но мне сильно помогли, опробовав finereader и скинув мне результаты - у меня бы до него руки не дошли. И тебе большое спасибо за natasha
# Детали
с парсингом pdf делал 3 разных подхода, каждый из которых требовал большого количества ручного труда и обработки всё новых и новых исключений
1) pdf -> txt, по тексту распарсить комментарии
2) pdf -> excel с помощью finereader (двумя частями)
3) pdf -> excel с помощью adobe acrobat (примерно по 2 тыщи страниц)
вариант 1: сложно разделить коммент от резолюции на него, в остальном норм
вариант 2: finereader вытаскивает весь текст и пытается сохранить структуру, но у него средненько получается: при том, что (по памяти) из 3 столбцов pdf он сохраняет в 15 столбцов excel, в первом столбце excel может оказать значение из третьего столбца pdf, и так часто происходит с хоть сколько-нибудь длинными комментариями. Поэтому я вытащил оттуда все строки, что выглядят корректно, добавил номера страниц к каждой строчке и "сойдёт"
но Ярослав, инициатор затеи, просил меня поднажать ещё, что с finereader'ом дальше выходило очень с трудом, поэтому переходим к варианту 3
вариант 3: acrobat хорошо сохраняет структуру, значения из одного столбца pdf оказываются в ~7 столбцах excel, их остаётся только объединить.
Однако, сохраняя максимум информации (даже картинки из pdf и отступы в тексте), имеет очень неприятный side-effect в том, что разные строчки внутри одной ячейки текста pdf оказываются на разных строках excel и нужно нащупывать, где граница между ячейками, а всё, что между - соединять. Также проблема с номерами страниц, он их игнорирует, но я попробую обогатить их из варианта 2. А также остаётся проблема с всякими объединёнными ячейками и переносами страниц
самый жизнеспособный в итоге вариант 3, сохраняет всю инфу и тд, но тоже требует ручной работы (много разнообразных исключений с первой проблемой). я его касался в последний раз 2 недели назад, прошёл большую часть, бросил из-за нехватки времени. Но постараюсь довести до конца всё же на днях по мере сил. Эту историю, к сожалению, сложно паралеллить с кем-то