



ES
Size: a a a
2019 March 02
2019 March 04
PK
Всем, привет. А какой benchmark suite сейчас самый признный в сообществе для измерения перфа спарка?
AM
Может кто работал с GraphX при помощи java. Есть какие то example и мануалы?
D
надо провести merge двух датафреймов (A и B) по ключу, при этом если запись (может быть только одна или ноль) уже существует, то надо провести по колонкам некоторые операции (сумма, взять min|max и т.д.),
кроме того как сделать left join и пробежаться по всем записям есть другие решения?
кроме того как сделать left join и пробежаться по всем записям есть другие решения?
Union + row_number потом применяешь фильтр row_number=1, с group by проблема нужно будет на каждую колонку агрегирующую функцию применять
2019 March 05
AM
Коллеги. Как можно оптимизировать distinct в Rdd? У меня одна операция занимает 80% времени от остальных. Хелп)
PK
distinct - это shuffle, поэтому оптимизация distinct - это правильное партиционирование, т.е. По ключу дистинкта
AM
distinct - это shuffle, поэтому оптимизация distinct - это правильное партиционирование, т.е. По ключу дистинкта
Я новичок, поэтому не совсем понял фразу про правильное партиционирование по ключу дистинкта.
AM
Т.е мне необходимо в дистинкте указать что то типа myRdd.distinct(myRdd..getNumPartitions())?
K
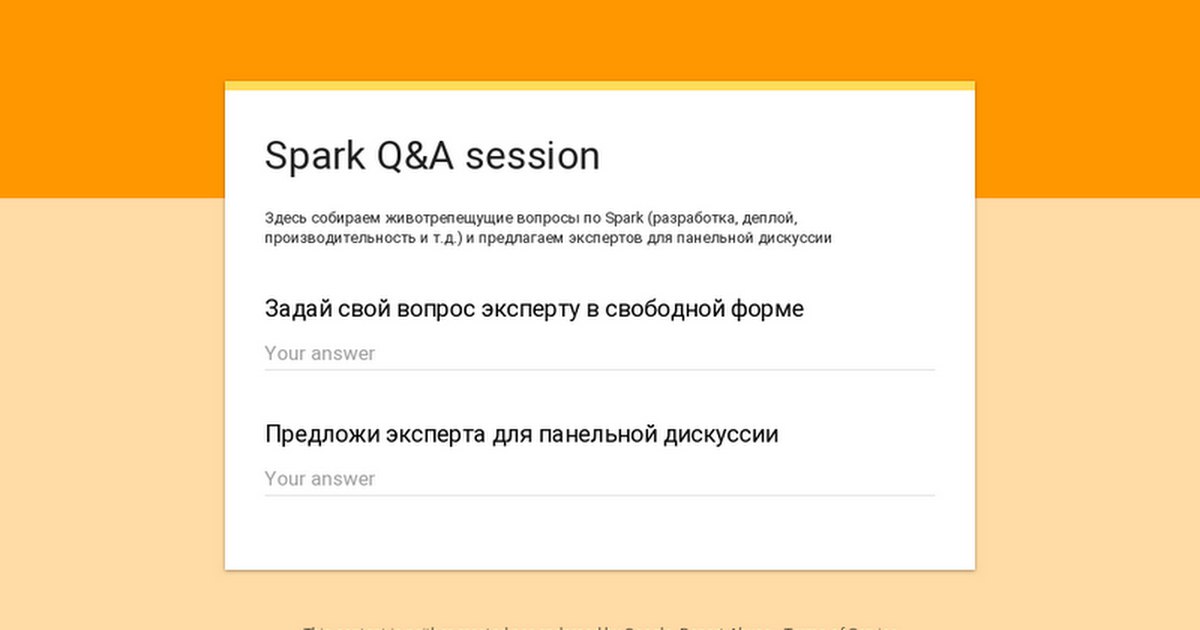
Привет, друзья, давно не слышались! Я вот раздумывал над новыми форматами для нашего митапа, и пришла в голову такая идея. Ко мне периодически обращаются за консультациями или просто задают вопросы по Spark. И чуть менее, чем всегда вопросы довольно однотипные. Как спланировать ресусры, как деплоить, есть ли какой-то стайл гайд, почему ALS такой тормозной. Я подумал, что на все вопросы никто из нас правильных ответов не знает. А если и знает, то, возможно, они не совсем правильные. Короче предлагаю на очередном митапе провести а-ля панельную дискуссию, гда мы соберем вместе нескольких экспертов и позадаем им животрепещущие вопросы. А во время дискусси родится истина. Мы эту истину осмыслим и упакуем в какой-нибудь документ (например статью на Хабр тиснем). Постепенно будем собирать знание и будет всем счастье. Задавать насущные вопросы и предлагать экспертов можно в этой форме https://goo.gl/forms/a51IZyeVunfZ2gbz2
а есть какие результаты?
t
Я новичок, поэтому не совсем понял фразу про правильное партиционирование по ключу дистинкта.
у тебя яблоки лежат в одной корзине, бананы во второй, апельсины в третьей. Если ты отдашь их трем людям, то они посчитают distinct почти моментально
t
но если все фрукты в корзинах будут перемешаны, то каждый человек будет считать уникальные фрукты у себя и это займет больше времени
AM
Да, но у меня все фрукты помешаны...
t
вот об этом тебе @pklemenkov и говорит
AM
Шафл необходим, но я не знаю делает ли комбайн
AM
т.е хотя бы частично убирать дубликаты, потом шафл
PK
а есть какие результаты?
Негусто пока, всего 4 ответа. Но я другую штуку придумал, на днях разошлю
С
Фруктов захотелось
2019 March 06
PK
Приведут-приведут, все будет в лучшем виде
2019 March 07
N
Подскажите . Если я , например, делаю join двух датафрэймов в spark sql или просто пишу join, то и в том и другом случае сработают все оптимизации
PK
“Просто пишу join” - это что значит? RDD джойнишь?