AS
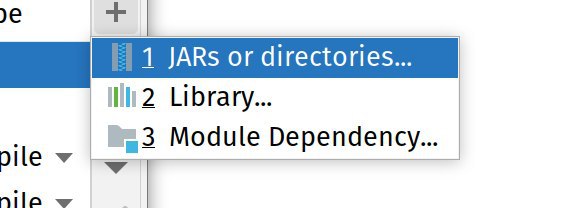
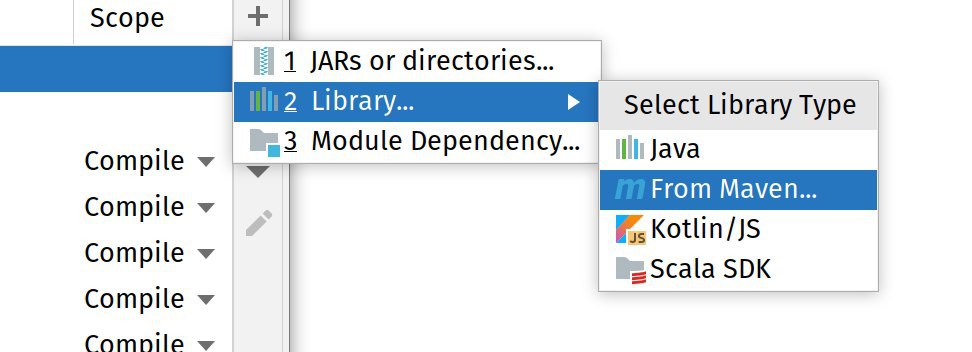
В тулбаре в IDEA есть кнопка, которая ведёт в настройки модуля, куда можно добавить недостающие зависимости, которые не удалось синхронизировать автоматически из цеппелина
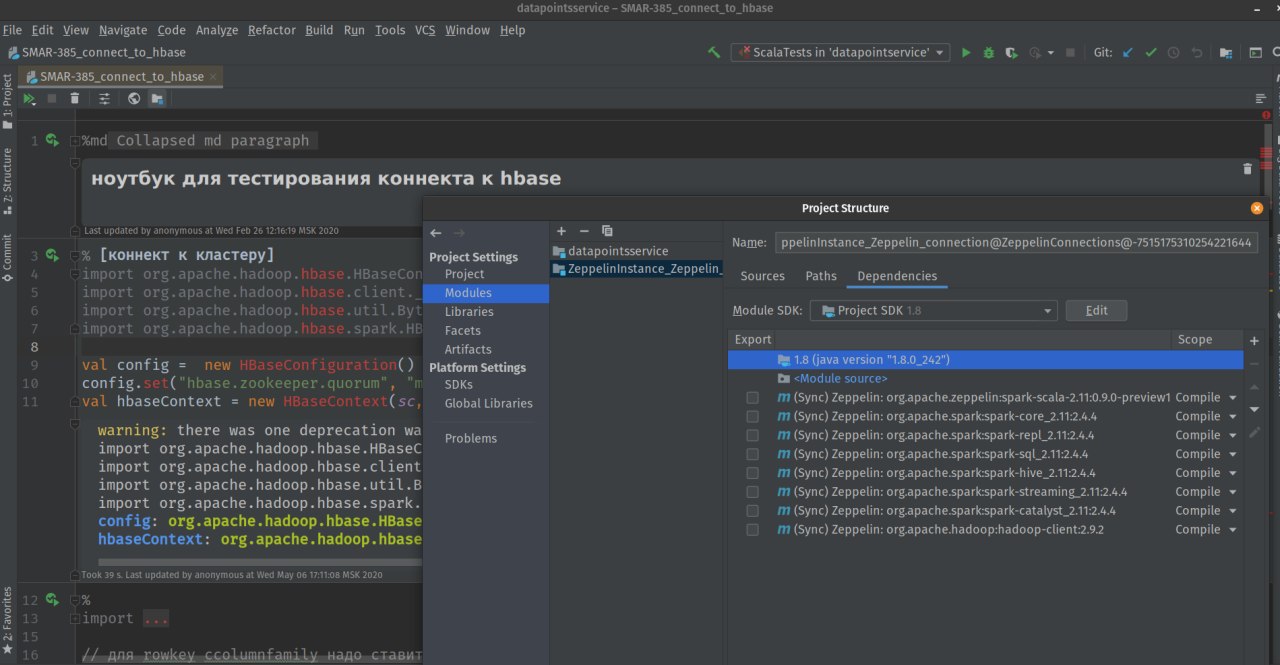
а где эта волшебная кнопка, мне каждый jar добавлять руками?
Size: a a a
AS
NA
NA
NA
AS
AS
VK
DC
java.lang.IllegalArgumentException: Field "col1" does not exist когда создаю пайплайн и пытаюсь зафитить дату.val data = this.spark.read
.format("csv")
.option("header", "true")
.option("mode", "DROPMALFORMED")
.load(this.taskConfig.training.db + this.taskConfig.training.table)
R
DC
R
R
R
DC
AS
OI
AS
OI