Всем, привет! Вчера обещал написать про фичу, которая порадует питонистов в грядущем релизе 2.3. Это фича - векторизованные UDF. Все, наверное, знают, что Spark становится реально хорош для питонистов, если пользоваться DataFrame и не пользоваться RDD. Потому что DataFrame API для PySpark - это просто тонкая обертка над скаловским рантаймом, которая не сериализует объекты на каждый чих. Подробнее об этом можно узнат в моем уроке по оптимизации вычислений на Spark
https://www.coursera.org/learn/big-data-analysis/lecture/RvIwy/welcomeТак вот, магический и очень крутой проект Apache Arrow
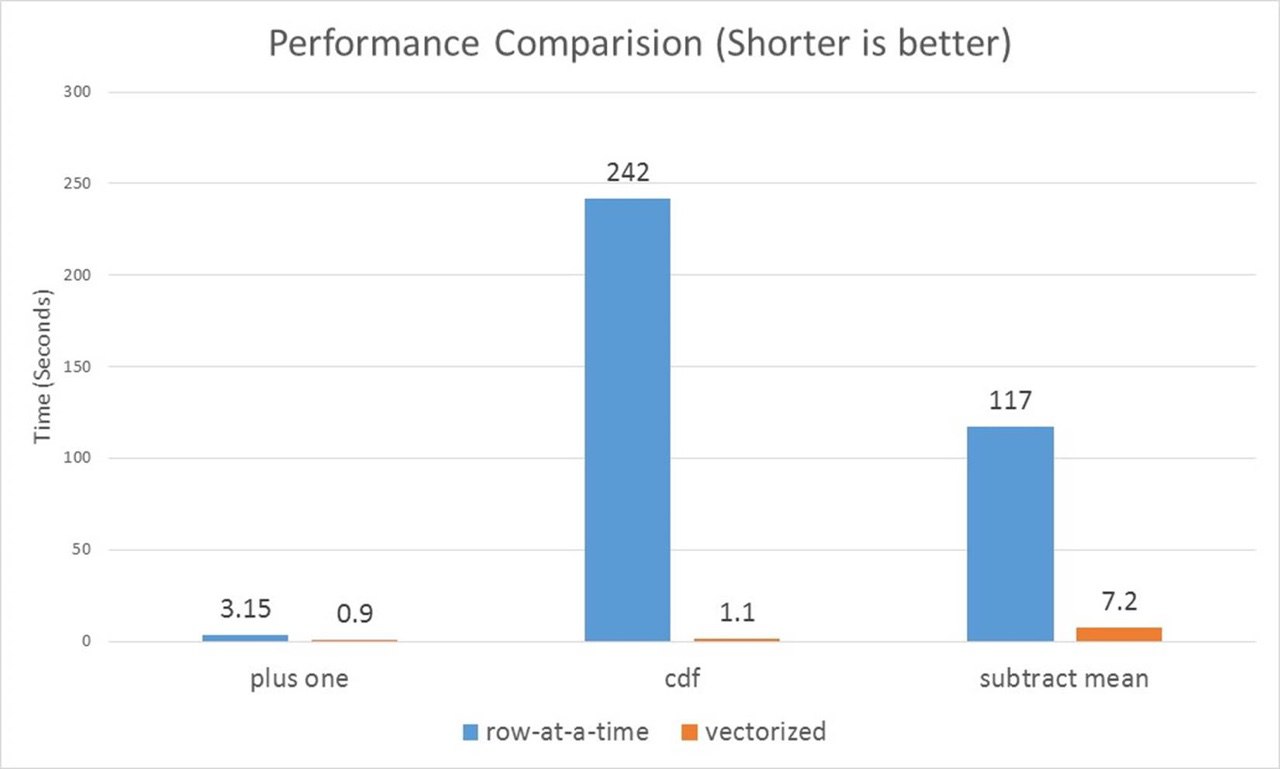
https://arrow.apache.org/ помог реализовать эту фишку. Интерфейс остался похожим, за исключением того, что векторизованные UDF-ки работают с pandas.Series. Бенчмарки показывают, что производительность растет от 3.5 до 250 раз в зависимости от задачи. Подробней можно почитать в этом посте
https://databricks.com/blog/2017/10/30/introducing-vectorized-udfs-for-pyspark.html@ser0t0nin , предлагаю вам потестить вашу уберджобу по напилке фичей для рекомендаций и поделиться результатами на следующем митапе!