



PK
Size: a a a
2019 April 17

PK
Ссылка на лайв
С
Господа подскажите пожалуйста, а spark.jdbc умеет вызывать процедуры в терадате?
N
Сюткин
Господа подскажите пожалуйста, а spark.jdbc умеет вызывать процедуры в терадате?
А ванильный jdbc умеет ?
С
Умеет
AK
В spark jdbc идет запрос формата select * ftom ( <your query> ) t так что если только функцию позвать... ну либо есть preStatement, который может например данные вставить во временную таблицу
С
В spark jdbc идет запрос формата select * ftom ( <your query> ) t так что если только функцию позвать... ну либо есть preStatement, который может например данные вставить во временную таблицу
Спасибо большое
2019 April 18
YG
Спасибо за доклады
YG
Любимый слайд
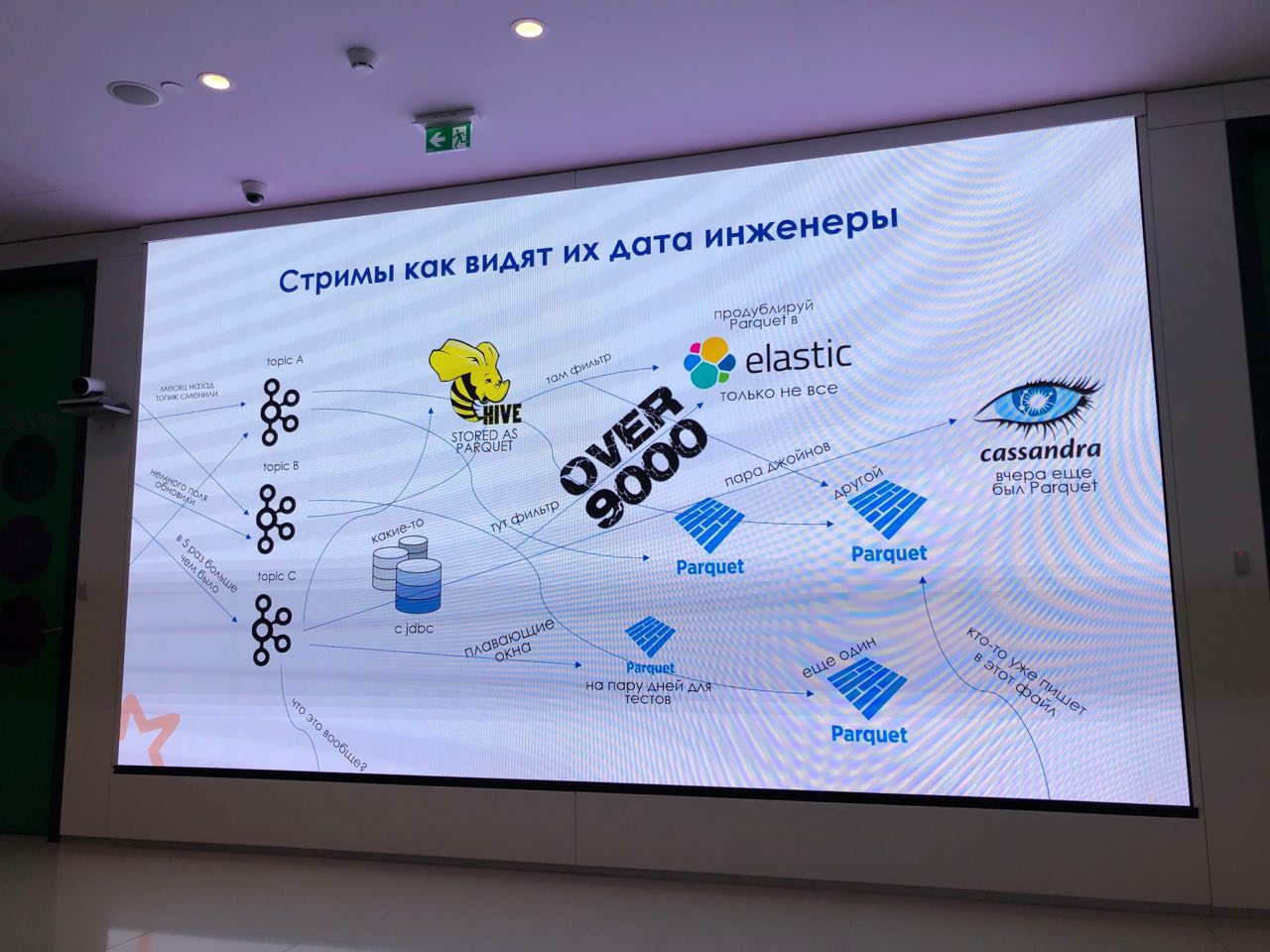

K
Ждём записи
OP
Ждём записи
Со стрима же есть https://youtu.be/YO6FYpme8kE
Ds
Там bottleneck в чем?
EN
Ио синка
EN
Вообще спасибо за мероприятие организаторам, мегафону за площадку 😊
На уровне 👌
На уровне 👌
PK
Вообще спасибо за мероприятие организаторам, мегафону за площадку 😊
На уровне 👌
На уровне 👌
Спасибо )
PK
Вчерашние презентации здесь https://drive.google.com/open?id=1mPGgkoKf-g_Wf-ljGoK8-y1nz0xjSS5B
Запись лайва доступна здесь https://www.youtube.com/watch?v=YO6FYpme8kE&feature=youtu.be, на нашем канале попозже перезальем
Запись лайва доступна здесь https://www.youtube.com/watch?v=YO6FYpme8kE&feature=youtu.be, на нашем канале попозже перезальем
2019 April 23
AA
Решил я для оптимизировать утилизацию ресурсов через запуск параллельных джобов внутри одного аппликешна согласно этой статье https://towardsdatascience.com/3-methods-for-parallelization-in-spark-6a1a4333b473 через треды. Выйгрыша как такового не получил, как и максимальную утилизацию ресурсов. Подскажите, есть ли профит от подобного на реальных системах, и такое используют в проде (я про пример с тредами из статьи)?

PK
Anton Alekseev
Решил я для оптимизировать утилизацию ресурсов через запуск параллельных джобов внутри одного аппликешна согласно этой статье https://towardsdatascience.com/3-methods-for-parallelization-in-spark-6a1a4333b473 через треды. Выйгрыша как такового не получил, как и максимальную утилизацию ресурсов. Подскажите, есть ли профит от подобного на реальных системах, и такое используют в проде (я про пример с тредами из статьи)?
Какой именно метод использовал? Треды на локальной тачке?