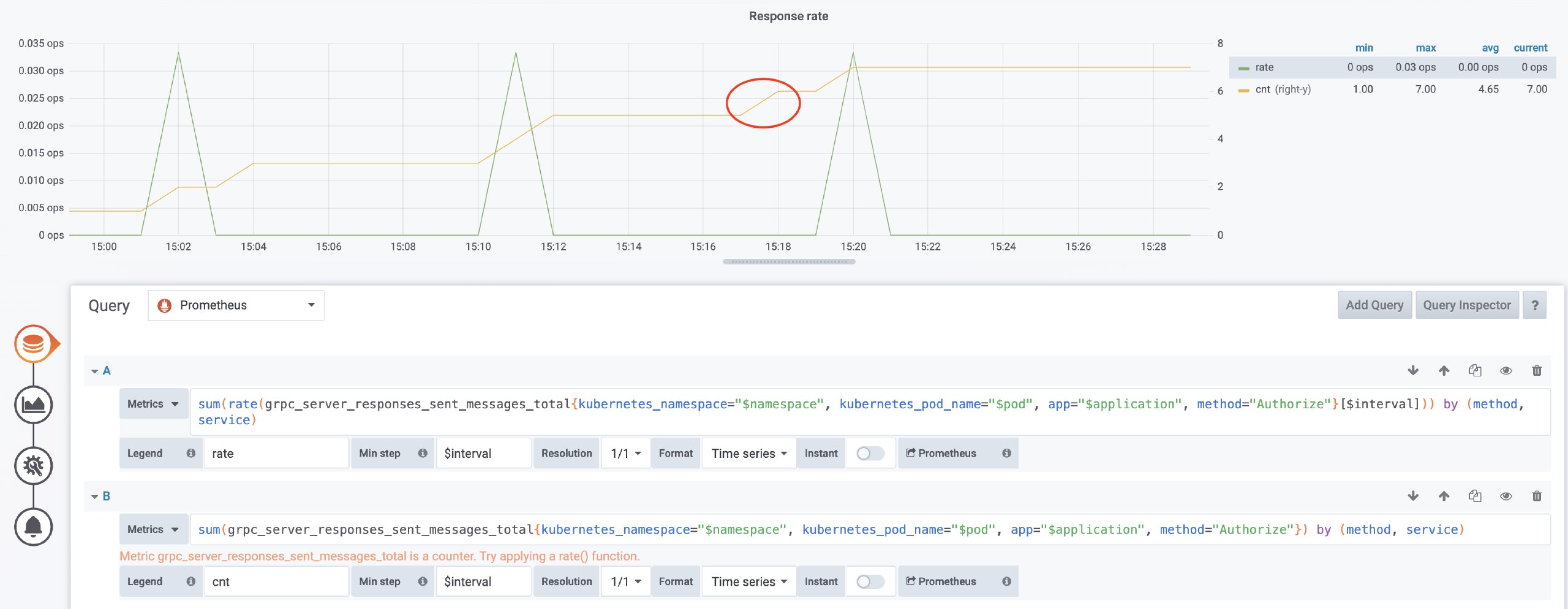
Ну это в некотором роде позор😕 Я бы, конечно, не отказался смотреть на эти данные, как на примерные, но я бы хотел понимать, насколько они примерные.
Судя по всему, нужно переходить на rollup от VM. Но только у меня почему-то VM на тестовом контуре, а на прод её ставить не хотят.
Это не позор, это такова предметная область: ты не тратишь кучу ресурсов на сбор и хранение точных данных, но за это расплачиваешься погрешностями при сборе метрик (timestamp выставляется в prome-е и может расходиться с временем актуальности метрики в экспортере), при хранении и при обработке (точка, в конечном счете, должна быть выровнена по периоду таймсерии, что уже само по себе вызывает необходимость в интерполяции).
Если тебе нужны абсолютно точные данные (например, потому что тебе нужно хранить бизнес-метрики), то prom (и, вообще, системы для работы с техническими метриками) — неподходящий для этого инструмент.