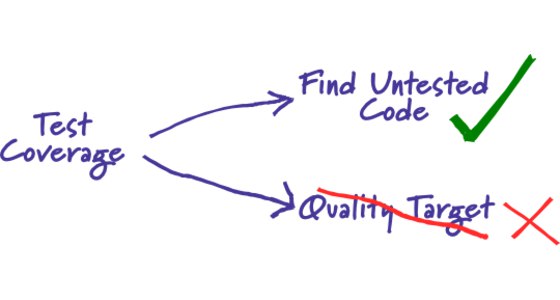
Жабысриптеры, привет) Я буду скидывать сюда ссылки на классные статьи про JavaScript и JavaScript библиотеки 💩
Size: a a a
<p>{message.text}</p>,
Post.findAll({
where: { 'or': [{authorId: 12}, {authorId: 13}] }
});
Post.findAll({
where: { [Op.or]: [{authorId: 12}, {authorId: 13}] }
});
Op.or это Symbol, что не позволяет злоумышленику так просто сделать ORM Injection.========= Запрос к бэкенду ======
50ms: Kyiv -------запрос-----> SF
20ms: работа бэкенда
50ms: Kyiv <------ответ------- SF
========= TCP соединение ========
50ms: Kyiv -------syn--------> SF
50ms: Kyiv <------syn/ack----- SF
50ms: Kyiv -------ack--------> SF
========= Запрос к бэкенду ======
Kyiv -------запрос-----> SF
20ms: работа бэкенда
50ms: Kyiv <------ответ------- SF
========= TCP соединение ========
50ms: Kyiv -------syn--------> SF
50ms: Kyiv <------syn/ack----- SF
50ms: Kyiv -------ack--------> SF
========= TLS соединение ========
Kyiv ---представление--> SF
50ms: Kyiv <--сертификаты----- SF
50ms: Kyiv ---обмен ключами--> SF
50ms: Kyiv <--обмен ключами--- SF
========= Запрос к бэкенду ======
50ms: Kyiv -------запрос-----> SF
20ms: работа бэкенда
50ms: Kyiv <------ответ------- SF
const reducer = (a, b) => a + b;
// Оба варианта должны дать одинаковый результат
[1, 2, 3, 4].reduce(reducer);
[1, 2, [3, 4].reduce(reducer)].reduce(reducer);
const reducer = (a, b) => a + b;
// Оба варианта должны дать одинаковый результат
[1, 2, 3, 4].reduce(reducer);
[4, 2, 1, 3].reduce(reducer);
========= TCP соединение ========Скорость в 100Мбит/с говорит о том, что мы получим 50KB через 4ms, но на самом деле у нас это займет 620ms.
50ms: Kyiv -------syn--------> SF
50ms: Kyiv <------syn/ack----- SF
50ms: Kyiv -------ack--------> SF
========= TLS соединение ========
Kyiv ---представление--> SF
50ms: Kyiv <--сертификаты----- SF
50ms: Kyiv ---обмен ключами--> SF
50ms: Kyiv <--обмен ключами--- SF
====== HTTP запрос к серверу ====
50ms: Kyiv -------запрос-----> SF
20ms: работа бекенда
50ms: Kyiv <-----14.6KB------- SF
50ms: Kyiv -------ack--------> SF
50ms: Kyiv <-----29.2KB------- SF
50ms: Kyiv -------ack--------> SF
50ms: Kyiv <-----6.2KB-------- SF