Если немного упороться и раскурить статью одного китайца, то можно прямо в пучарме настроить ремоут интерпретер где есть спарк и говнякать прямо из пучарма.
да cost чего угодно, open source проект обычно не представляют "бесплатный ..." Databricks Community Edition бесплатный, GitHub Codespaces пока бесплатный..
ну наверное так и надо сказать, запускайте open source jupyter на своем текущем железе - это бесплатно у меня легкая идиосинкразия когда open source выставляют как "бесплатное" в первую очередь... я так и представляю как на конференции объявляют: "Линус Торвальдс, разработчик бесплатного ядра операционной системы"
Ну ядро совсем бесплатное же! Опенсорс не всегда бесплатный, как мы знаем, но обычно всё что можно собрать и запустить самому удобно считать бесплатным
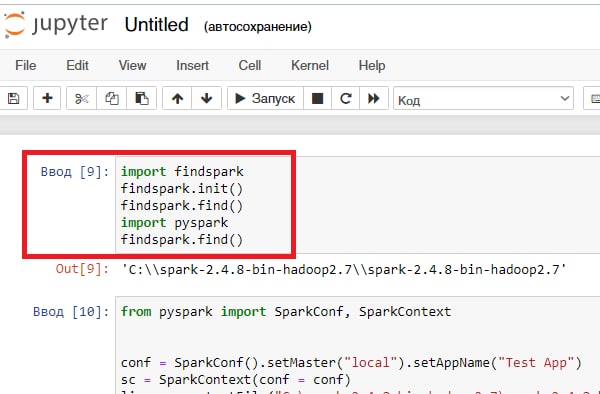
С танцем с бубном поднял Jupyter и Spark на винде. Вопрос - блок с findspark теперь всегда придется добавлять, при разработке любого скрипта? Т.е. как бы помогать Jupiter найти инстанс спарка при каждом запуске?
Сори за небольшой офтоп, но, мне кажется, проще и полезнее завести линух и делать это сразу в нем, гемора в разы меньше. А насчёт файндспарка - можно и без него, просто задай переменные окружения (spark_home, etc)