



AM
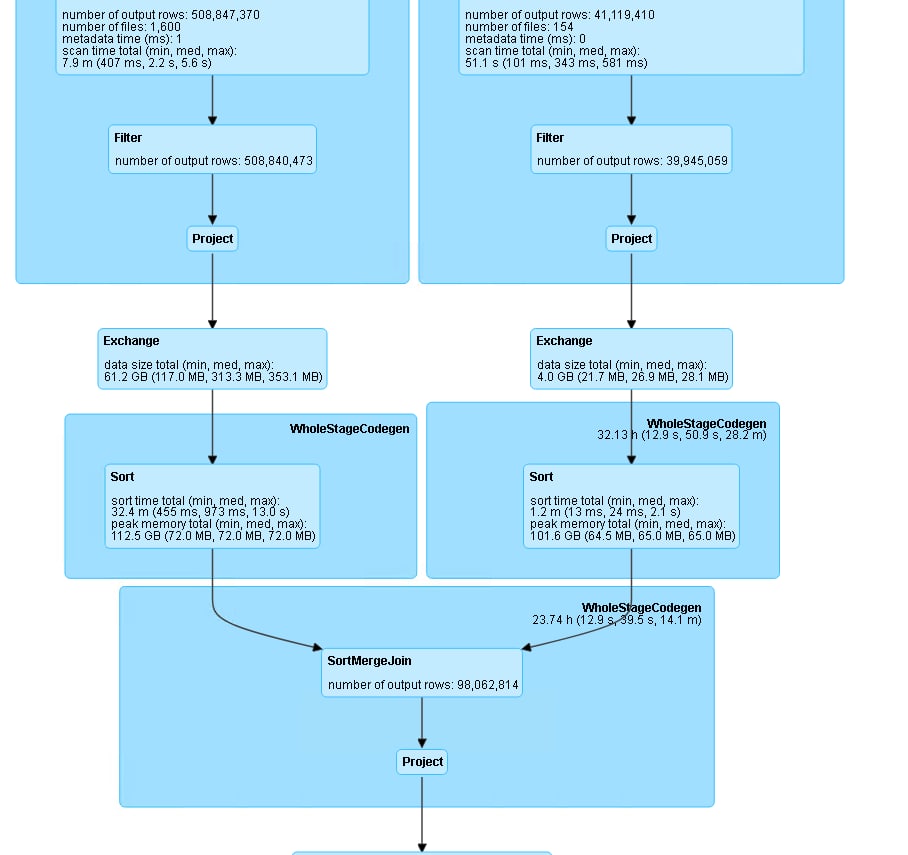
граф выполняемого запроса если наведет на какую мысль
Size: a a a
AM
K
KS
А
select cast(1.1 as double)*cast(1.1 as double)*cast(1.1 as double) as dbl, cast(1.1 as decimal(2,1))*cast(1.1 as decimal(2,1))*cast(1.1 as decimal(2,1)) as dcml
KS
KS
A
KS
ИК
KS
KS
KS
ИК
KS
KS
KS
AS
VM
N
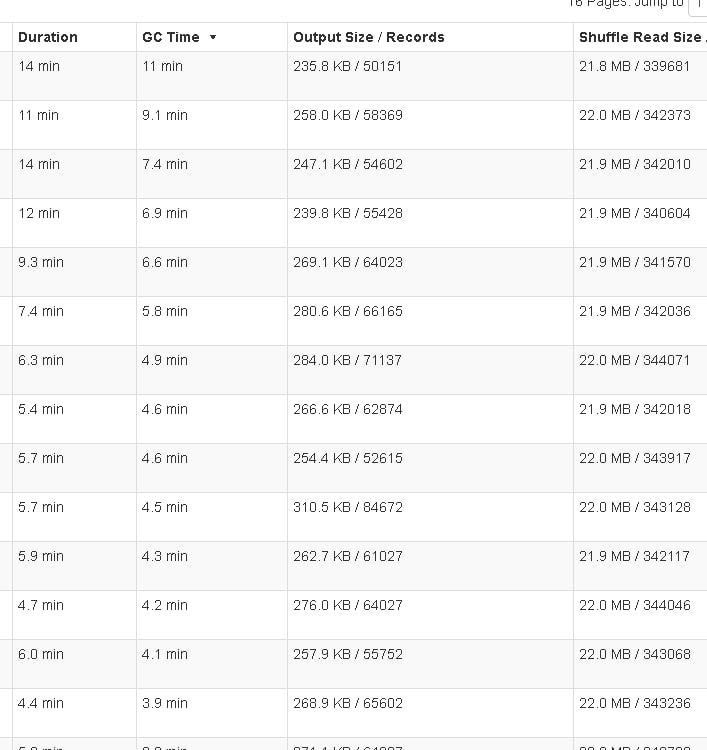
AM
