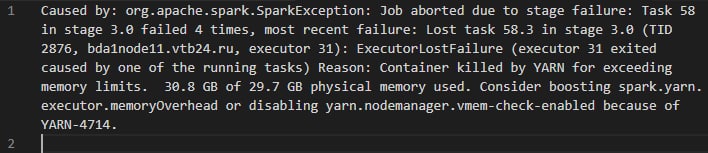
DN
Всем привет, есть кто в БД шарит?
Вопрос: есть один запрос - 3 таблицы связаны лефт джойнами
можно же его разбить на два - сначала 2 связать. потом третью к результату?
Вопрос: есть один запрос - 3 таблицы связаны лефт джойнами
можно же его разбить на два - сначала 2 связать. потом третью к результату?
можно