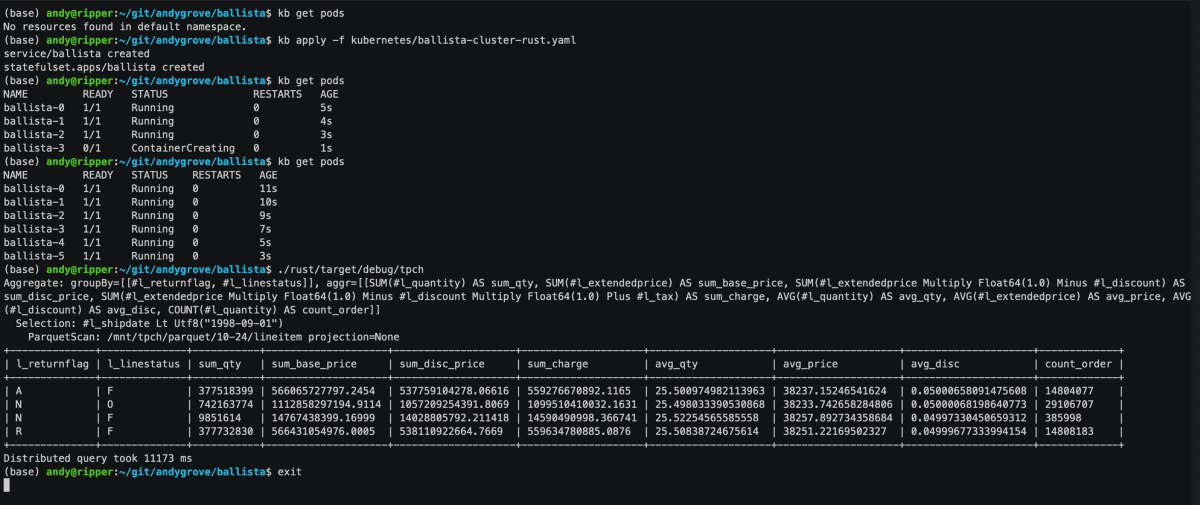
The combination of Rust and Arrow also results in much lower memory usage than Apache Spark — up to 5x lower memory usage in some cases. This means that more processing can fit on a single node, reducing the overhead of distributed compute
=/ меньше ешь памяти, значит больше можно на машинку написать, хотя упираешься ты чаще в cpu
И ещё наверное меньше ресурсов уходит на SerDe, не знаю сколько это в процентах от общей нагрузки, 2% или 20%, если значительно, то пропускная способность будет выше.