дяденьки, поможите, а? почему после моего стильного и элегантного кода каталог с мелкими файлами не компактится, а пухнет?
Сжатие и сортировка данных в исходных файлах? Скорее всего их изрядно причесали прежде чем слить на диск(глянуть бы код которым их писали) А компактер при чтении-записи все данные взболтал репартишеном.
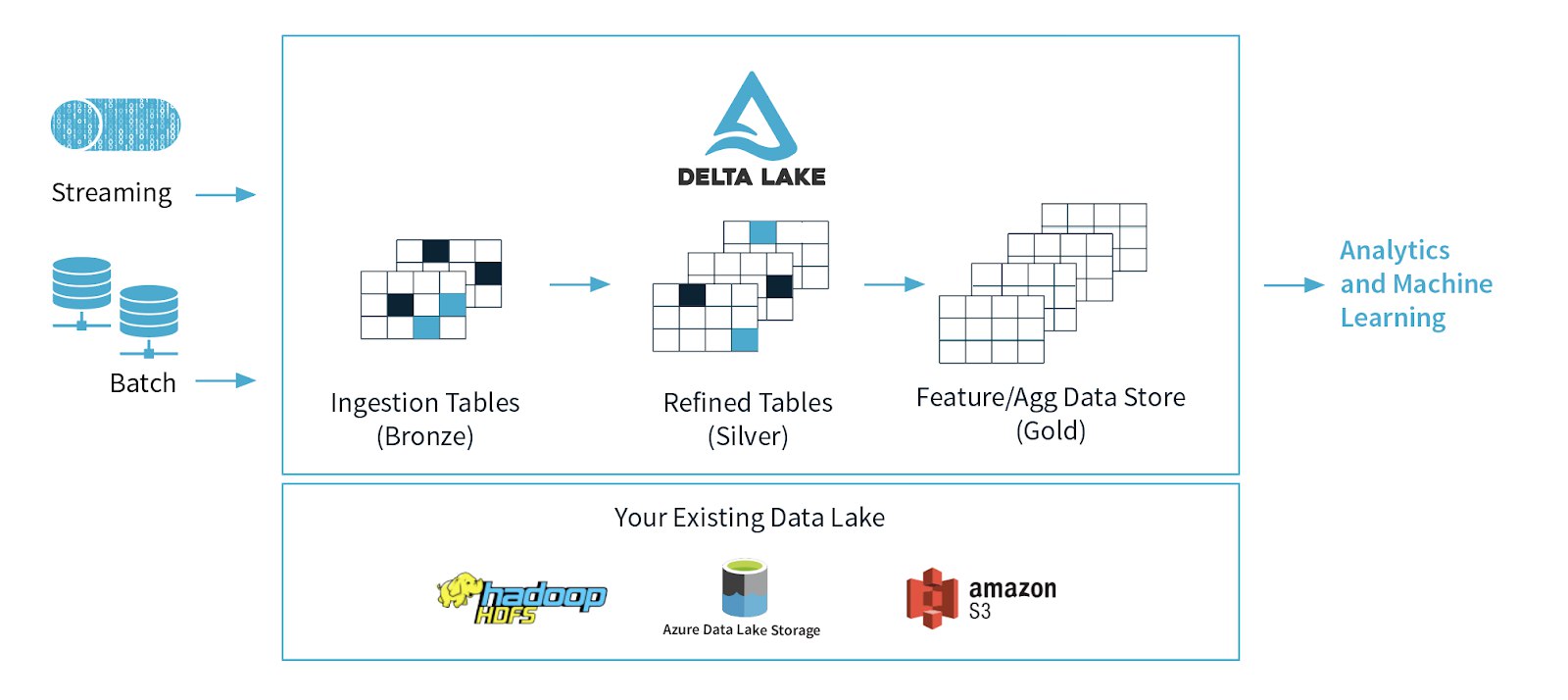
Увидел в пути bronze и вспомнил про bronze/silver/gold концепт, который мы стараемся имплементить. Можете кинуть, что почитать на эту тему. Какие данные в каком уровне хранятся, какие best practices...
в колонках не получится вот так просто компактить сортировка и правда дает очень приличное сжатие поэтому надо лезть в дебри дф и повторять операции на выходе (что не всегда оправдано)
Всем привет! Сейчас планируем разворачивать Hadoop. Есть ли какие-то требования к томам на ОС? Как лучше оформить структуру файловой системы/директорий lдля NN и DN? Требования к месту?
Всем привет! Сейчас планируем разворачивать Hadoop. Есть ли какие-то требования к томам на ОС? Как лучше оформить структуру файловой системы/директорий lдля NN и DN? Требования к месту?
Всем привет! Сейчас планируем разворачивать Hadoop. Есть ли какие-то требования к томам на ОС? Как лучше оформить структуру файловой системы/директорий lдля NN и DN? Требования к месту?
никак хадуп не умрет ) один том на один диск для датанод все точки монтирования скормить в конфиг хадупу
Добрый день. Коллеги, прощу прощения за возможно банальный вопрос, но что означают «звездочки» в phisical plan спарка: *(1) FileScan *(2) Filter *(2) Sort
Для всех типов операций она означает отдно и то же?
Добрый день. Коллеги, прощу прощения за возможно банальный вопрос, но что означают «звездочки» в phisical plan спарка: *(1) FileScan *(2) Filter *(2) Sort
Для всех типов операций она означает отдно и то же?
* значит, что у вас spark.sql.codegen.wholeStage выставлен в true