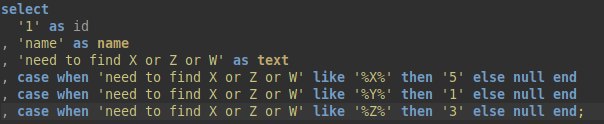
update: Преобразовал текстовик в json — > в dataFrame (получился key, value), теперь нужно сделать как в sql, только для 1 строки в df искать все значения(word) из словаря:
{"word": "abandons", "value": "-2"}
{"word": "abducted", "value": "-2"}
{"word": "abduction", "value": "-2"}
{"word": "abductions", "value": "-2"}
и если есть совпадения - то в новый(отдельный столбец делать сумму value)
C помощью какой функции можно это сделать? Или есть более простой способ это реализовать, чем мой