



BK
Спасибо, я походу понял в чем проблема
Size: a a a
BK
R
BK
BK
АШ
BK
OI
18:22:13 ERROR YarnClientSchedulerBackend: The YARN application has already ended! It might have been killed or the Application Master may have failed to start. Check the YARN application logs for more details.
ERROR SparkContext: Error initializing SparkContext.
Container exited with a non-zero exit code 1. Error file: prelaunch.err.
WARN DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
Exception in thread "main" java.lang.NoSuchFieldError: NONE
ME
ME
ME
OI
ME
AS
ME
ME
OI
ME
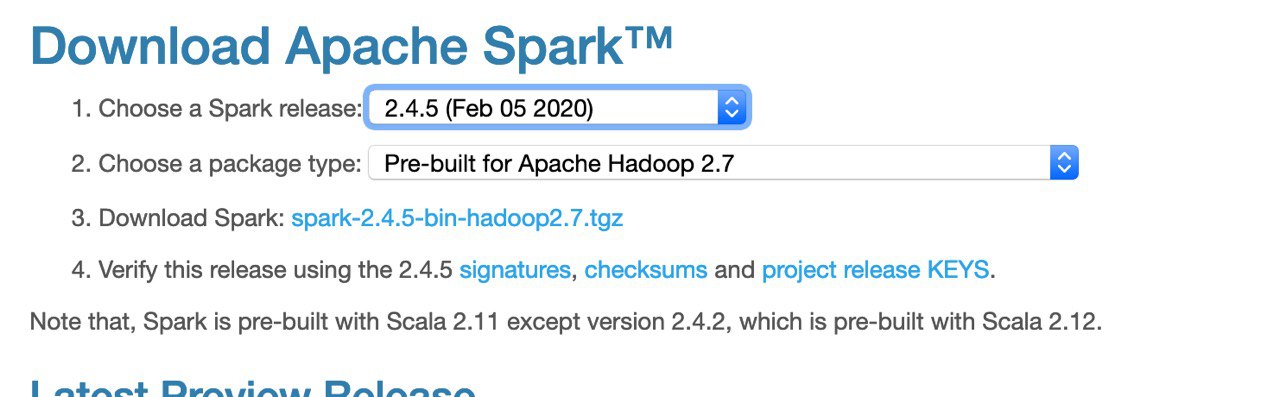
ME
ME
OI
