Предлагаешь брать умственноотсталых в любом случае?
Если у человека нет нужных знаний, но есть желание учиться и развиваться, то это плюс. Хотя умение гуглить базовые вопросы должно быть изначально, имхо.
Если у человека нет нужных знаний, но есть желание учиться и развиваться, то это плюс. Хотя умение гуглить базовые вопросы должно быть изначально, имхо.
А в спарке реально через стриминг получить доступ к данным из предыдущих батчей? Обработать - положить , в след батче так же положить и проверить например их объединение ? Например поток данных вида (ip, ts), хочется выделять сессии и сохранять куда нить только сессии. Без отдельной инмемори никак ?
А в спарке реально через стриминг получить доступ к данным из предыдущих батчей? Обработать - положить , в след батче так же положить и проверить например их объединение ? Например поток данных вида (ip, ts), хочется выделять сессии и сохранять куда нить только сессии. Без отдельной инмемори никак ?
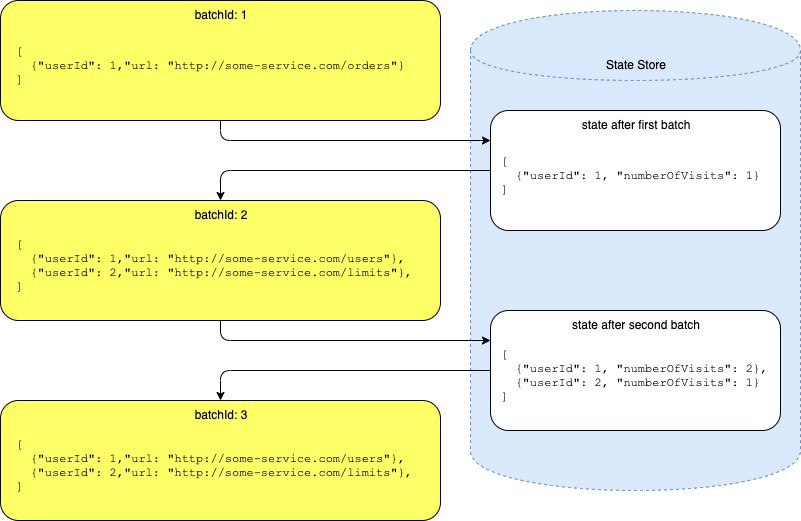
либо, если не хочется заморачиваться со всеми этими стейтами, можно просто реализовать логику через foreachBatch по типу: - записали батч в s3 с айдишником - прочитали предыдущий айдишник - склеили с текущим батчем - записали новый батч.
Не инклюзивность, а дайвёрсити. А вообще спасибо админам, что не дают ронять уровень. Чтобы не было, как в чяте одной _аналитической_субд, где людям отвечают, как элементарный sql написать, а 80% остальных вопросов в поиске не ниже 5 строки выдачи гугла.