EI
.option("sampleSize", "500000")
Тоже не подбирает, даже с таким количеством.
Тоже не подбирает, даже с таким количеством.
Size: a a a
EI
AZ
AZ
EI
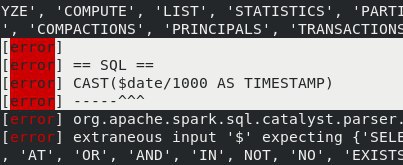
modified на $dateEI
AZ
EI
EI
RI
The node /hbase is not in ZooKeeper. It should have been written by the master. Check the value configured in 'zookeeper.znode.parent'. There could be a mismatch with the one configured in the master. но перед этим есть сообщение INFO ZooKeeperRegistry: ClusterId read in ZooKeeper is nullRI
DP
O
DP
O
O
DP
A
A
A