VE
Суть в чём:
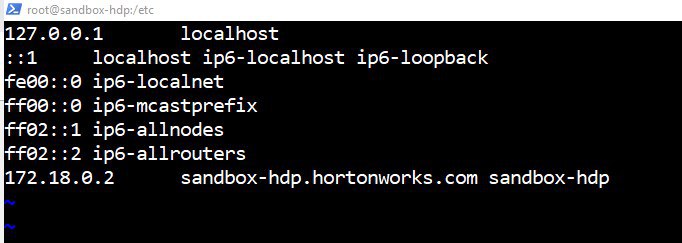
hdfs://sandbox-hdp.hortonworks.com:8020" - это правильно
Там алгоритм такой:
1. Java client конектится к неймноде по 8020 и спрашивает куда записывать данные
2. Неймнода смотрит на свои ноды и даёт айпи одной из датанод куда писать (или хостнейм, зависит от настроек)
3. Java client принимает айпи (или хостнейм) и пытается записать данные. НО, так как у тебя это всё в докере, неймнода думает что айпи дата ноды это 127.0.01
hdfs://sandbox-hdp.hortonworks.com:8020" - это правильно
Там алгоритм такой:
1. Java client конектится к неймноде по 8020 и спрашивает куда записывать данные
2. Неймнода смотрит на свои ноды и даёт айпи одной из датанод куда писать (или хостнейм, зависит от настроек)
3. Java client принимает айпи (или хостнейм) и пытается записать данные. НО, так как у тебя это всё в докере, неймнода думает что айпи дата ноды это 127.0.01