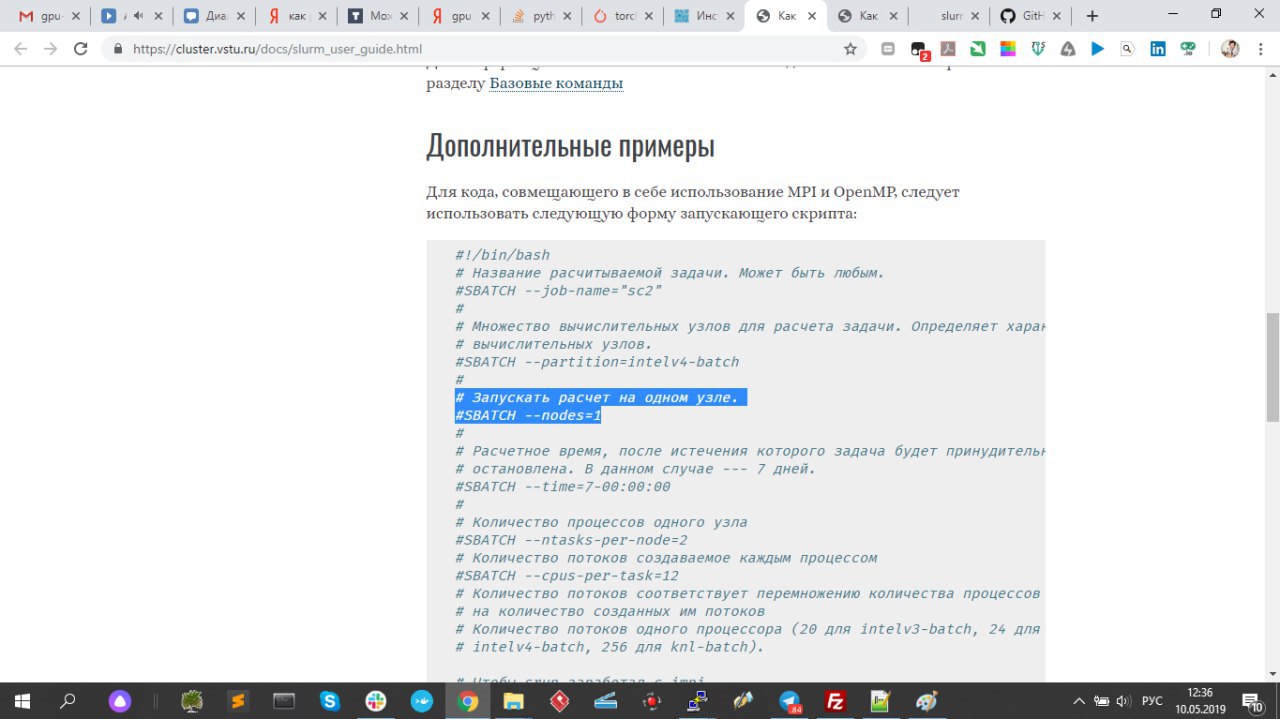
возможно не умный вопрос задаю, просто я почитал документацию ..и тут написано #SBATCH —nodes=2 достаточно для того, чтобы распределить вычисления по 2-м узлам.
https://cluster.vstu.ru/docs/slurm_user_guide.html(скриншот1)
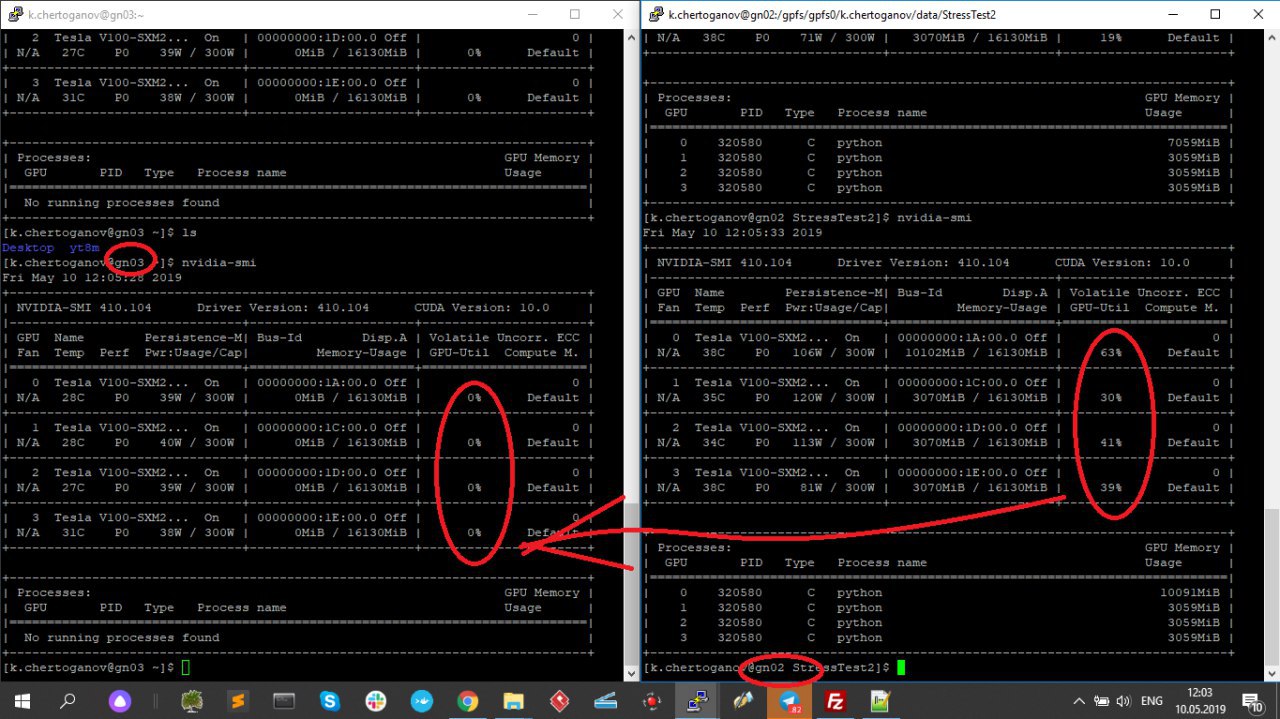
я запускаю расчет на двух узлах.
#SBATCH —nodes=2
а получается что на одном узле gn02 все 4GPU загружены, а на второй узле gn03 (скриншот №2) GPU-шки простаивают.
я выделил себе две ноды..хочу чтобы по двум нодам параллельно считало..
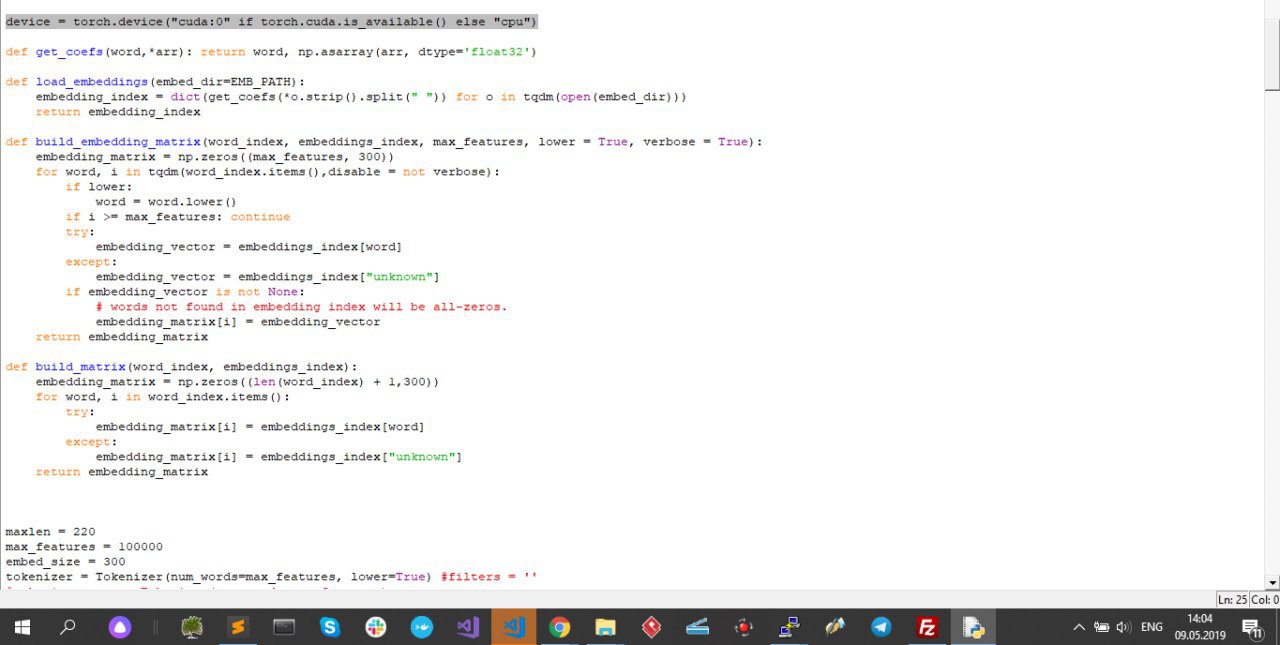
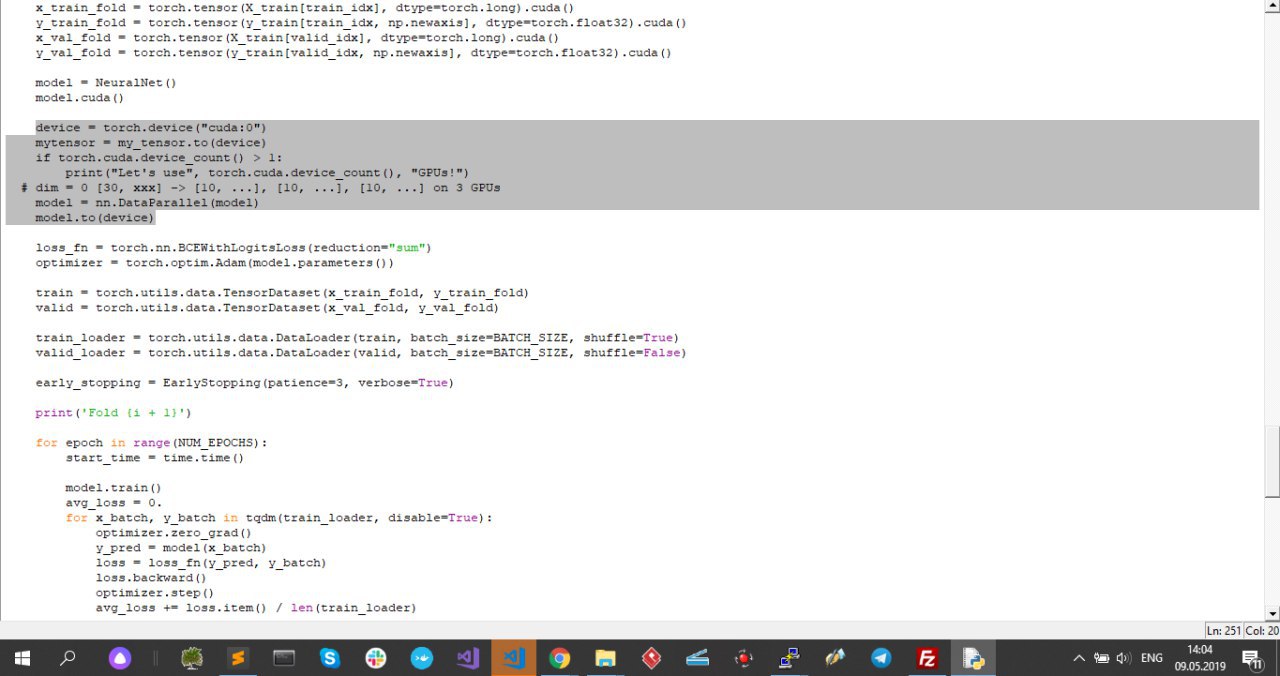
В коде программы я ее распаралелил (как показывал раньше, скриншот3), так что тут все норм..
как мне распараллелить вычисления теперь на 2 ноды ? на одну полностью все загружает, хочу чтобы по двум нодам параллельно вычисления шли..
P.S.
я подумал, что нужно просто прописать
# Количество процессов одного узла
#SBATCH —ntasks-per-node=4
и результат такой же, это был JobID 57044,
теперь поставил
#SBATCH —ntasks-per-node=8
это был JobID 570448
результат и там такой же (скриншот 5 и 6)