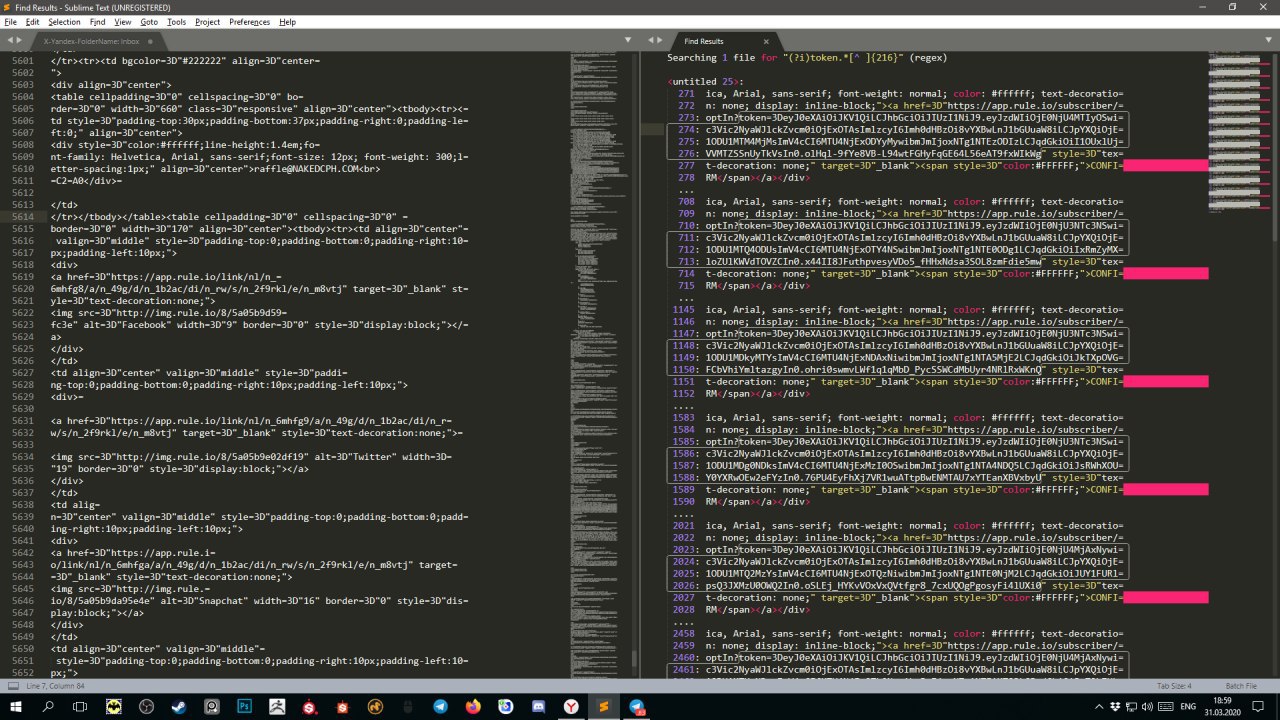
Есть тхт файл,в котором объединены тысячи писем,мне нужно извлечь все ссылки с токеном.Токен я регулярным выражением нашел,возможно ли сразу его объеденить с первой часть ссылки, либо сразу извлечь ссылку с токеном регуляркой.
Ещё вопросы. 1. Откуда взялся файл? 2. Чем именно файл обрабатывается?
Значит обрабатывается вручную. Первое, удалите инвалидные переносы строк =\r\n они рвут контексты и никакие выражения ничего хорошего в исходном файле вам не извлекут
1.Письма скачаны с the bat/авточекером почт. 2.Sublime любая подобная программа
Это костыль, а не помощь. Переносы строк мешают. Забирайте файл каким нибудь нормальным инструментом (не знаю каким), который строки не разбивает переносом.
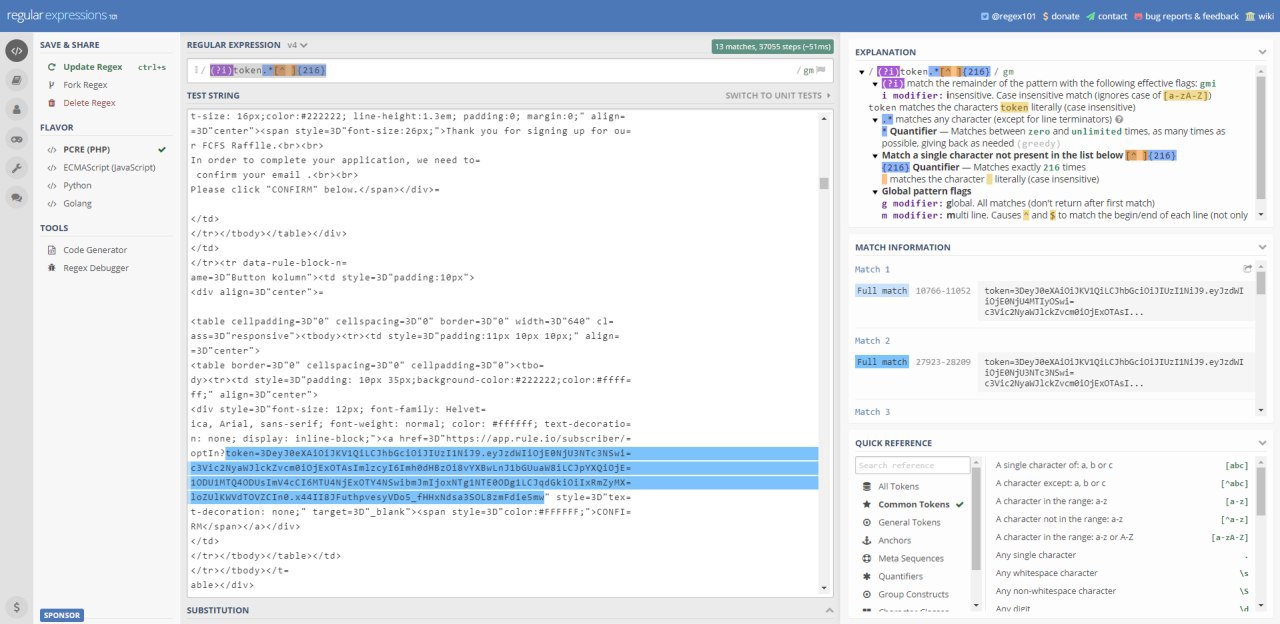
Всем привет.Есть регулярное выражение https://regex101.com/r/6NW6A2/5 вытаскивающее информацию после token.Возможно ли его сразу объединить регуляркой с первой частью ссылки,чтобы лишний раз в таблицу не переносить?
Добрый день. Подскажите, каким образом можно автоматом заполнить пустые ячейки? При этом чтобы значения были "плавными", этакий градиент от одного значения к другому. Извините, не знаю как грамотно это назвать. Нашел только инструкцию для эксель, там это решается с помощью Геометрической прогрессии, но для Гугл таблиц такого скрипта не нашел
Добрый день. Подскажите, каким образом можно автоматом заполнить пустые ячейки? При этом чтобы значения были "плавными", этакий градиент от одного значения к другому. Извините, не знаю как грамотно это назвать. Нашел только инструкцию для эксель, там это решается с помощью Геометрической прогрессии, но для Гугл таблиц такого скрипта не нашел
Добрый день. Подскажите, каким образом можно автоматом заполнить пустые ячейки? При этом чтобы значения были "плавными", этакий градиент от одного значения к другому. Извините, не знаю как грамотно это назвать. Нашел только инструкцию для эксель, там это решается с помощью Геометрической прогрессии, но для Гугл таблиц такого скрипта не нашел