Implicit Deep Latent Variable Models for Text Generation.Le Fang at el. University at Buffalo
arxiv.org/abs/1908.11527.pdfiVAE. Как VAE, только лучше.Deep latent variable models (LVM), такие как вариационные автоэнкодеры, начинают играть важную роль в генерации текста. Благодаря гладкому непрерывному латентному пространству можно интерполяцией генерировать текст (например, в контексте диалога) и выполнять векторные перобразования для перноса стиля.
Репрезентативная способность текущих LVM ограничена:
(1) предположением о нормальности распределения (posterior) латентных переменных при заданных входных данных
(2) коллапсом posterior, когда декодер становится к нему нечувствителен. Причина этого, вероятно, в неоправданности предположения (1) для конкретных данных.
Для решения данных проблем предлагается:
- iVAE (VAE from apple (нет))
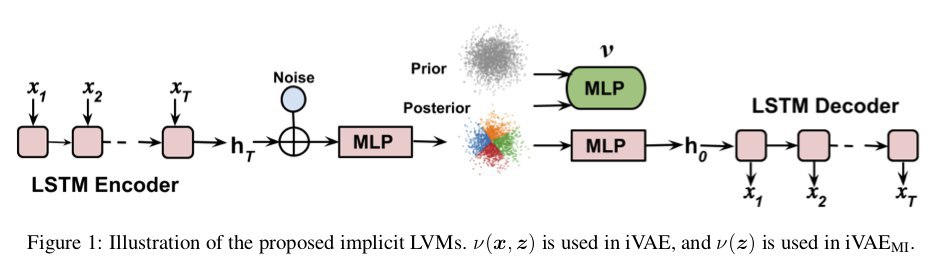
инсайт статьи: вместо сильного (слишком) предположения о нормальном распределении латентных переменных используется вспомогательная нейронка (авторы называют её не иначе как многослойный перцептрон MLP), которая производит распределение латентных переменных, получая на вход ембединг входных данных из енкодера и гаусовский шум.
- iVAEMI максимизируем взаимную информацию между латентным представлением и входом, получая соответcтвие каждому предложению локальной области в латентном пространстве.
Особое великолепие заключено в репозитории, позволяющем
воспроизвести все результаты статьи последовательностью скриптов на питоне, где код читается легче матана в статье.
🏆
SOTA-языковое моделирование. На датасете Penn Tree Bank (PTB)
🏆
SOTA-языковое моделирование. На датасете Yahoo.
🏆
SOTA-языковое моделирование. На датасете Yelp corpora.
🎭 П
еренос стиля - превращение негативных комментариев Yelp в позитивные (и наоборот). Добавляется сентимент-классификатор (многослойный перцептрон), енкодер и классификатор учатся состязательно, используются два различных декодера: для позитива и негатива. Примеры в статье вдохновляют достаточно, чтобы вызвать недоверие и желание воспроизвести.
💬
Генерация ответа в диалоге. Используя несущие смысловую нагрузку истории диалога латентные переменные, генерируется ответ на датасетах Switchboard и Dailydialog.