



Size: a a a
2016 September 03
2016 September 06
Интересная тулза для бэкапа - restic - https://restic.github.io/
Fork - еще один клиент Git для Mac - https://git-fork.com/
Интересный проект для проброса локальных портов веб-сервера (к примеру) в Интернет через их сервис - https://ngrok.com
И последнее на сегодня, утилита для порт форвардинга написаная на Go — https://blog.kintoandar.com/2016/08/fwd-the-little-forwarder-that-could.html

А сорри не все, еще есть коллекция плагинов для Logstash, там много всего интересного - https://github.com/logstash-plugins

2016 September 09
Minio - объектно ориентированное хранилище данных на подобие S3 от Amazon. Реализация написана на языке GO, и сам продукт очень прост в устоновке и обладает встроенным Web-интерфейсом.
Очень интересная и стоящая штука, зацените - https://github.com/minio/minio
Очень интересная и стоящая штука, зацените - https://github.com/minio/minio

2016 September 12
Foreman is an open source application that can be used to manage, provision, configure, and monitor a single or group of servers. Foreman smart proxy architecture allows you to automate repetitive tasks, quickly deploy applications, proactively manage change using configuration management systems such as Puppet, Chef and Salt —- https://theforeman.org/introduction.html
интересная тулза на которую стоит обратить внимание
2016 September 20
Набор модных и открытх шрифтов для кодинка и разработки - https://github.com/powerline/fonts

Включая Hack, Meslo, Tinos
DropBox следит за вами... или просто использует грязные приемы на вашем Мас - https://habrahabr.ru/post/310074/?utm_campaign=email_digest&utm_source=email_habrahabr&utm_medium=email_week_20160920&utm_content=link2post
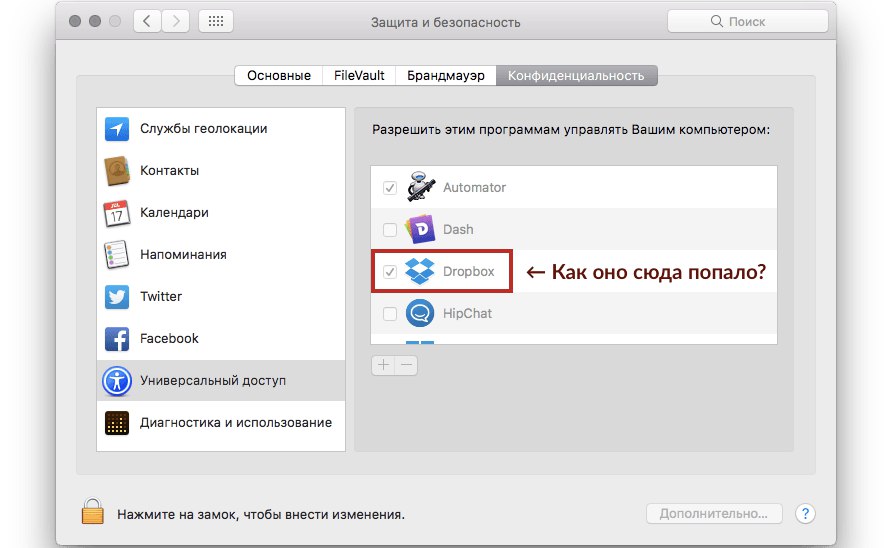
Ну и наконец крутанское чтиво!
Полное практическое руководство по Docker: с нуля до кластера на AWS - https://habrahabr.ru/post/310460/

2016 September 21
Вышла новая Apache CouchDB 2.0 - https://blog.couchdb.org/

In short,
1) fault tolerance: data is stored on more than one computer. A CouchDB 2.0 cluster obviates the need for custom setup of failover CouchDB instances.
2) performance: data is split up and only a part lives on each node in a cluster. That means each node only has a fraction of the work to do (like computing a view index) than a single node instance would have.
3) capacity: with setups of multiple computers storing data, and with data being split among nodes, it is now possible to store amounts of data in CouchDB that exceed the capacity of a single computer many many times, setting CouchDB up for genuine Big Data solutions.
1) fault tolerance: data is stored on more than one computer. A CouchDB 2.0 cluster obviates the need for custom setup of failover CouchDB instances.
2) performance: data is split up and only a part lives on each node in a cluster. That means each node only has a fraction of the work to do (like computing a view index) than a single node instance would have.
3) capacity: with setups of multiple computers storing data, and with data being split among nodes, it is now possible to store amounts of data in CouchDB that exceed the capacity of a single computer many many times, setting CouchDB up for genuine Big Data solutions.
И у них новое модное лого 😊

Кому впадлу читать на английском