



Size: a a a
2022 February 06

2022 February 07

Предлагаю запретить на paperswithcode считать код на матлабе за код.

2022 February 08
#prog #rust
Хозяйке на заметку
Иногда требуется писать реализации трейтов вроде
Но мы можем написать код так, чтобы компилятор таки помогал! Первый способ — это сделать newtype, который будет в реализации
Разумеется, у этого метода есть и недостатки. Это довольно ad-hoc решение, это бойлерплейт (вы же хотите добавить реализации
Для этих случаев годится другой способ. Мы можем воспользоваться тем фактом, что в let-биндинге может быть произвольный паттерн, который привязывает сразу несколько имён (а также тем фактом, что, начиная с версии 1.26, привязка ссылки к паттерну по значению привязывает суб-паттерны по ссылке) и явно показать, что какие-то поля мы игнорируем. Опять покажу на примере:
Хозяйке на заметку
Иногда требуется писать реализации трейтов вроде
PartialEq и Hash, для которых код не укладывается в прямолинейную схему derive-макросов. Например, в коде должны использоваться не непосредственно значения полей, а некоторая их комбинация, или же одно из полей должно быть проигнорировано при сравнении. Для того, чтобы разговор был более конкретным, покажем конкретный тип:struct Big {
field: u32,
another: Vec<u8>,
one_more: (i32, i32),
irrelevant: String,
}
Напишем для этого типа реализацию PartialEq, которая будет игнорировать поле irrelevant. Казалось бы, всё просто:impl PartialEq for Big {
fn eq(&self, rhs: &Self) -> bool {
self.field == rhs.field
&& self.another == rhs.another
&& self.one_more == rhs.one_more
}
}
Однако тут есть тонкий момент: если в структуру буду добавлены новые поля, то нужно будет не забыть дописать их сравнение в реализацию — и компилятор нам тут никак не поможет. Более того, исключения сравнения одного поля для программиста выглядит, как ошибка, и без поясняющего комментария следующий программист может "исправить" код и нарушить его логику.Но мы можем написать код так, чтобы компилятор таки помогал! Первый способ — это сделать newtype, который будет в реализации
PartialEq::eq безусловно возвращать true:struct UnconditionallyEqual<T>(T);
impl<T> PartialEq for UnconditionallyEqual<T> {
fn eq(&self, _other: &Self) -> bool {
true
}
}
В этом случае достаточно поменять тип поля irrelevant на UnconditionallyEqual<String> — и можно будет использовать стандартный #[derive(PartialEq)] для достижения требуемого функционала. Бонусом мы получим очень хорошую передачу намерений, которая видна другим программистам.Разумеется, у этого метода есть и недостатки. Это довольно ad-hoc решение, это бойлерплейт (вы же хотите добавить реализации
Deref и DerefMut для удобства, верно?), это иной тип, что иногда может мешаться и очень длинное имя. Вдобавок, иногда нам требуется просто возможность для какой-то одной функции проигнорировать одно или два поля, но не забыть остальные с учётом тех, что могут добавить в будущем — в этом случае подход с newtype-ом может оказаться недостаточно гибким и в целом оверкиллом.Для этих случаев годится другой способ. Мы можем воспользоваться тем фактом, что в let-биндинге может быть произвольный паттерн, который привязывает сразу несколько имён (а также тем фактом, что, начиная с версии 1.26, привязка ссылки к паттерну по значению привязывает суб-паттерны по ссылке) и явно показать, что какие-то поля мы игнорируем. Опять покажу на примере:
impl PartialEq for Big {
fn eq(&self, rhs: &Self) -> bool {
let Self { field, another, one_more, irrelevant: _ } = self;
*field == rhs.field
&& *another == rhs.another
&& *one_more == rhs.one_more
}
}
В этом случае код перестанет компилироваться, если мы добавим новые поля, так что возможность забыть их обработку исключена. Этот подход используется всюду в компиляторе самого Rust. Разумеется, это работает и с мутабельными ссылками.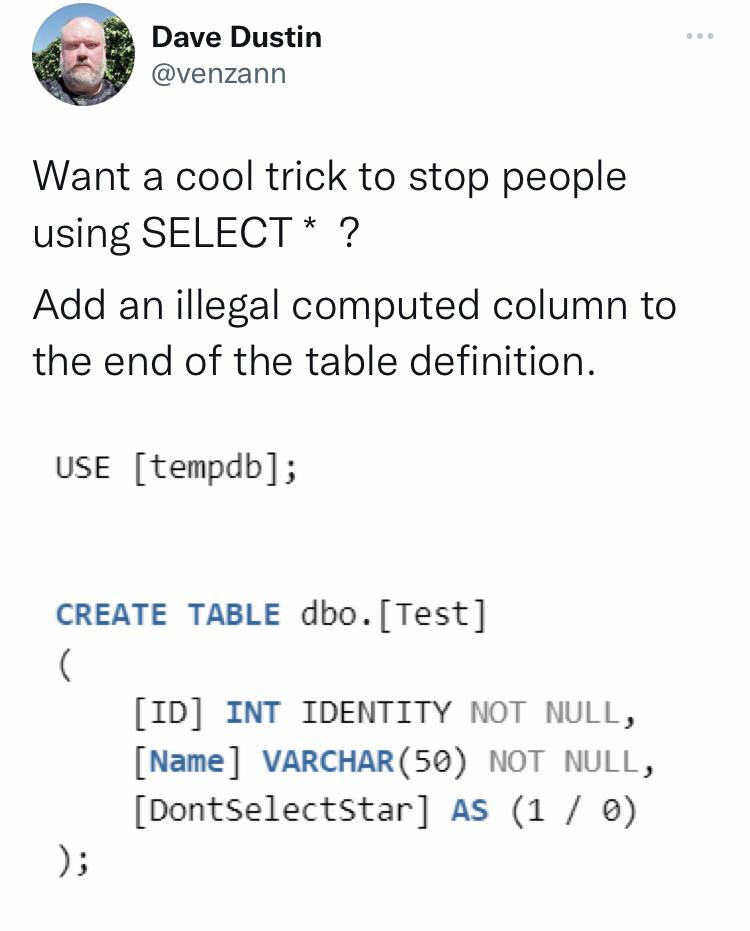
#мнеприслали
(Отредактировала, но постаралась сохранить слог автора).
Наверно, начать историю следует с того, что живу я в городе с населением 250 тысяч и уже третий год работаю в такси.
Итак, зимний вечер, бело-жёлто-чёрный Солярис, ваш покорный слуга за рулём, и две пассажирки обсуждают мужчин.
— Пойми, что принцев не бывает. Я вот недавно поняла, что всё, что надо, я могу сама купить. Или там мастера вызвать, чтобы починить. От мужчины мне нужны всего две вещи. Он должен мочь хотя бы два раза за ночь, и у него должна быть работа. Не в Газпроме, а просто нормальная приличная работа, на которой больничные оплачивают, — монотонно рассуждает одна из пассажирок.
Они еще много что говорили, но я запомнил только эту фразу. Потому что это ведь про меня. У нас в такси как раз незадолго до этого ввели больничные, даже для ИП, коим я и являюсь. Уже успел один раз заболеть и получить деньги. Это, кстати, моя первая работа, где выплачивают больничный. По количеству раз за ночь, поверьте, я тоже подхожу.
Получается, в свои 42 я вполне себе еще котируюсь на рынке женских фантазий. В ближайшие выходные я позвал сестру, мы поехали в торговый центр и купили мне приличную одежду. Я как-то ожил. Понял, что жизнь ещё не закончена. Может, даже и семья у меня ещё появится.
Зиму сменила весна. Не та весна, которая с серым снегом и лужами во дворе, а настоящая. С маленькими зелёными листиками, травой и тёплыми вечерами. Именно в такой вечер мы приехали на загородную турбазу, справлять свадьбу племянника.
Тосты, конверты с подарками и жизнерадостный тамада — всё как положено. Но совершенно внезапно среди гостей я узнаю ту самую пассажирку. Дожидаюсь первого же медленного танца, приглашаю её, и во время невнятного топтания по дощатому полу рассказываю эту историю…
Спустя четыре месяца мы съехались.
P.S. От редакции: мне кажется, это самая романтичная история про больничные.
Свои интересные, забавные и странные истории вы можете присылать мне на почту ereteeva@yandex.ru или в личку @ereteeva — самые-самые обязательно опубликую!ereteeva@yandex.ru или в личку @ereteeva — самые-самые обязательно опубликую!
(Отредактировала, но постаралась сохранить слог автора).
Наверно, начать историю следует с того, что живу я в городе с населением 250 тысяч и уже третий год работаю в такси.
Итак, зимний вечер, бело-жёлто-чёрный Солярис, ваш покорный слуга за рулём, и две пассажирки обсуждают мужчин.
— Пойми, что принцев не бывает. Я вот недавно поняла, что всё, что надо, я могу сама купить. Или там мастера вызвать, чтобы починить. От мужчины мне нужны всего две вещи. Он должен мочь хотя бы два раза за ночь, и у него должна быть работа. Не в Газпроме, а просто нормальная приличная работа, на которой больничные оплачивают, — монотонно рассуждает одна из пассажирок.
Они еще много что говорили, но я запомнил только эту фразу. Потому что это ведь про меня. У нас в такси как раз незадолго до этого ввели больничные, даже для ИП, коим я и являюсь. Уже успел один раз заболеть и получить деньги. Это, кстати, моя первая работа, где выплачивают больничный. По количеству раз за ночь, поверьте, я тоже подхожу.
Получается, в свои 42 я вполне себе еще котируюсь на рынке женских фантазий. В ближайшие выходные я позвал сестру, мы поехали в торговый центр и купили мне приличную одежду. Я как-то ожил. Понял, что жизнь ещё не закончена. Может, даже и семья у меня ещё появится.
Зиму сменила весна. Не та весна, которая с серым снегом и лужами во дворе, а настоящая. С маленькими зелёными листиками, травой и тёплыми вечерами. Именно в такой вечер мы приехали на загородную турбазу, справлять свадьбу племянника.
Тосты, конверты с подарками и жизнерадостный тамада — всё как положено. Но совершенно внезапно среди гостей я узнаю ту самую пассажирку. Дожидаюсь первого же медленного танца, приглашаю её, и во время невнятного топтания по дощатому полу рассказываю эту историю…
Спустя четыре месяца мы съехались.
P.S. От редакции: мне кажется, это самая романтичная история про больничные.
Свои интересные, забавные и странные истории вы можете присылать мне на почту ereteeva@yandex.ru или в личку @ereteeva — самые-самые обязательно опубликую!ereteeva@yandex.ru или в личку @ereteeva — самые-самые обязательно опубликую!
2022 February 09

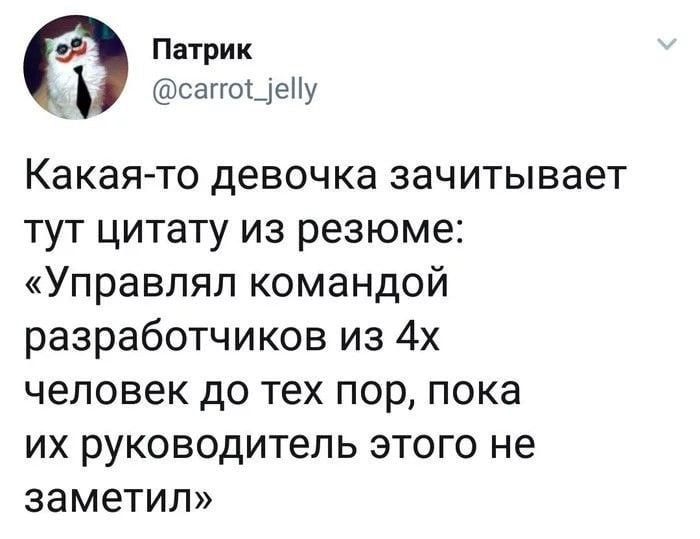
2022 February 10
#prog #rust #article от Амоса (и чуток про #go)
Some mistakes Rust doesn't catch
(thanks @ihatereality)
Some mistakes Rust doesn't catch
(thanks @ihatereality)

Наконец-то посмотрел более продвинутый доклад от того же автора:
— C++ and Beyond 2012: Herb Sutter - atomic Weapons 1 of 2
— C++ and Beyond 2012: Herb Sutter - atomic Weapons 2 of 2
Тоже очень интересный доклад, хоть и совсем не настолько beginner-friendly. Если вам интересно не только, как в общем работают атомики, но и почему они так работают и как использовать не
— C++ and Beyond 2012: Herb Sutter - atomic Weapons 1 of 2
— C++ and Beyond 2012: Herb Sutter - atomic Weapons 2 of 2
Тоже очень интересный доклад, хоть и совсем не настолько beginner-friendly. Если вам интересно не только, как в общем работают атомики, но и почему они так работают и как использовать не
SeqCst ордеринги — рекомендую!
2022 February 11

Там Вафель стримит, как он пишет на расте Bimap

🐝🗺
(и нет, Вафель, вот в этой ситуации использование хештега #wafflecontext более чем уместно)
(и нет, Вафель, вот в этой ситуации использование хештега #wafflecontext более чем уместно)
2022 February 12

Где-то — увы, не помню уже, где — читал про критерий роста себя, как писателя. Мол, если ты читаешь свои старые тексты годичной давности и они не вызывают у тебя желания переписать их, то ты остановился в развитии.
С применением этого принципа к себе у меня есть затруднения. С кодом это более-менее работает, а вот с текстами авторских постов — нет. Когда я перечитываю старые посты, у меня, бывает, возникает желание переписать некоторые корявые формулировки (а они бывают в силу того, что я пишу сразу начисто), но никогда не бывает желания переписать с нуля.
В предположении об истинности этого принципа возможны два случая. Первый — выглядящий крайне нереалистичным — то, что я уже пишу практически идеально. Второй — я действительно не развиваюсь и слеп к собственным недостаткам. В связи с этим я бы хотел узнать ваше мнение.
Что вы думаете о том, как я пишу? Что есть хорошего, а что стоит поменять? Хочу отметить, что я спрашиваю именно о слоге, а не о тематике.
С применением этого принципа к себе у меня есть затруднения. С кодом это более-менее работает, а вот с текстами авторских постов — нет. Когда я перечитываю старые посты, у меня, бывает, возникает желание переписать некоторые корявые формулировки (а они бывают в силу того, что я пишу сразу начисто), но никогда не бывает желания переписать с нуля.
В предположении об истинности этого принципа возможны два случая. Первый — выглядящий крайне нереалистичным — то, что я уже пишу практически идеально. Второй — я действительно не развиваюсь и слеп к собственным недостаткам. В связи с этим я бы хотел узнать ваше мнение.
Что вы думаете о том, как я пишу? Что есть хорошего, а что стоит поменять? Хочу отметить, что я спрашиваю именно о слоге, а не о тематике.
2022 February 13
Вчера я провёл стрим, где начал писать двухсторонюю хэшмапу. Т.е. если в обычной
Всё пошло не так, как бы хотелось (я это ожидал и поэтому не публиковал тут ссылку на стрим), но в итоге я смог написать
Вот тут можно посмотреть запись с вырезанными попытками починить стрим.
Я вроде смог настроить obs так, чтобы стрим больше не лагал, так что завтра продолжу писать
— Перейти с
— Дописать остальные методы, только с
— Написать итераторы
— etc
Завтра, вс, 2022-02-13, ~16:00 @ twitch.tv/wafflelapkin
HashMap отношение K -> V, то в BiHashMap отношение K <-> K'.
Всё пошло не так, как бы хотелось (я это ожидал и поэтому не публиковал тут ссылку на стрим), но в итоге я смог написать
BiHashMap с парой самых базовых методов вроде insert и lget.Вот тут можно посмотреть запись с вырезанными попытками починить стрим.
Я вроде смог настроить obs так, чтобы стрим больше не лагал, так что завтра продолжу писать
BiHashMap, там ещё много чего надо сделать:— Перейти с
StaticRc на что-то другое (на стриме объясню почему)— Дописать остальные методы, только с
new, insert и lget в этом всём нет смысла— Написать итераторы
— etc
Завтра, вс, 2022-02-13, ~16:00 @ twitch.tv/wafflelapkin