



SS
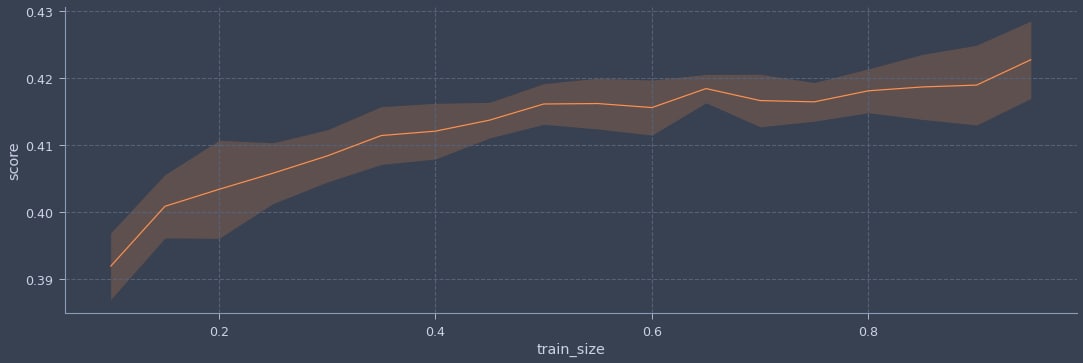
SGDClassifier, X: 50K x 1K, y: ~100 classes
Size: a a a
SS
DP
SS
DP
SS
DP
DP
SS
SS
DP
ч
Pandas возникла в 2008 году и на сегодняшний день является крайне популярной, если речь идёт о Data Science. Но ничто не вечно под луной и вот, появилась новая библиотека pypolars, которая уже сейчас может конкурировать с Pandas как минимум в плане производительности.
АК
i
АК
DP
DP
K
K
DP
DP