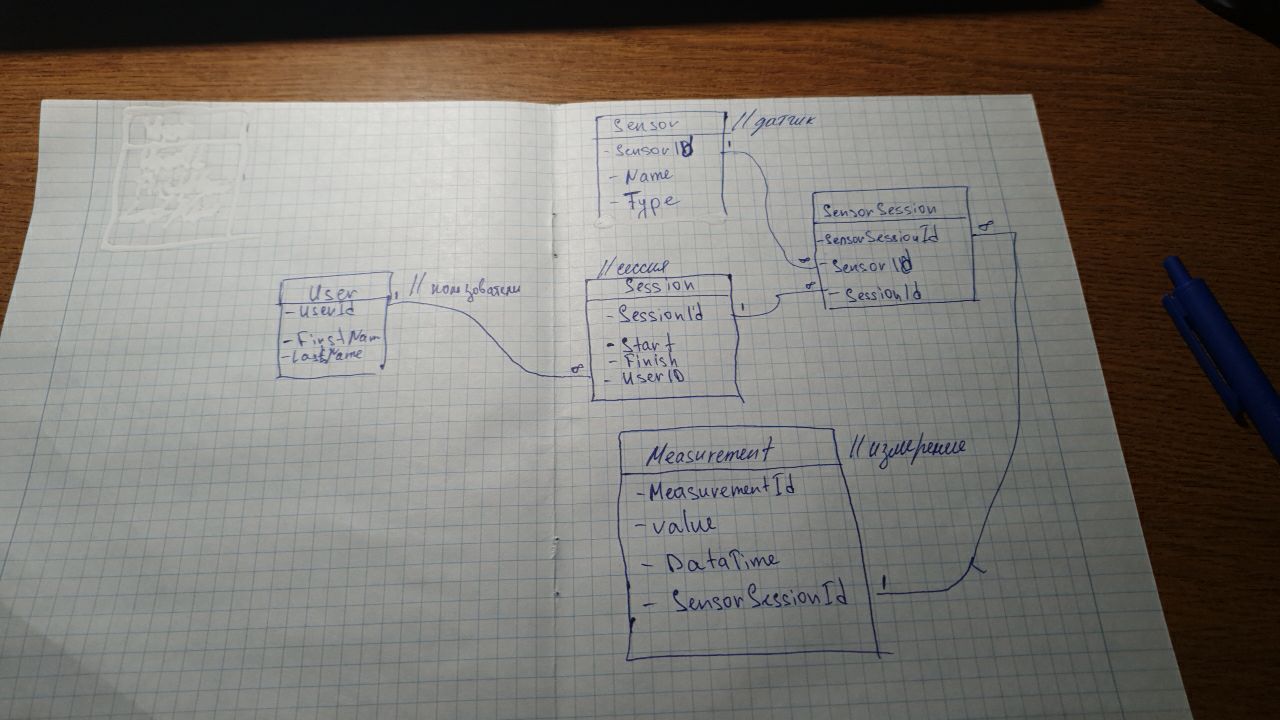
Проверить мой дизайн я начинающий, поэтому строго не судите
Условия:
Создаётся приложение для сбора и анализа информации с внешних датчиков. В
приложении выделены следующие сущности:
• Канал измерения – описывает канал поступления информации (датчик).
Характеризуется уникальным идентификатором, именем, типом канала.
• Измерительная сессия – один сеанс измерения. Основные характеристики: время
начала и завершения, набор задействованных каналов. Опционально может
присутствовать указание на пользователя, проводившего измерение.
• Измерение – совокупность измеренной величины, временной отметки, единиц
измерения. Измерение соотносится с измерительной сессией и каналом
измерения.
Необходимо разработать реляционное хранилище для указанных сущностей.
Вот мой дизайн
Единственное, что могу сказать, первичные ключи можно называть просто ID, а в связанной таблице внешний ключ соответственно <внешняя таблица>ID, как у вас. Но это не ошибка, так вроде все верно.