



k
перетестил, уходит траф на другие хосты при ревейте. ночью смотрел на паб сеть вместо привата, вот и не увидел изменений )))) спать видимо ночью надо )
Надо. А ты в бане))
Size: a a a
k
AM
ВН
AM
AM
AM
ВН
ВН
AM
AM
ВН
AM
N
N
L
L
Г
L
ВН
L
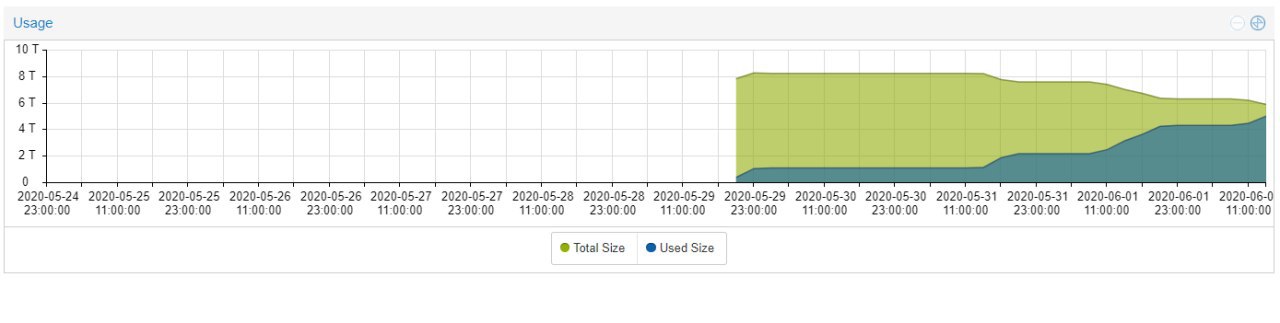
rados df --format json - там все в порядке с размером пулаsub status {
my ($class, $storeid, $scfg, $cache) = @_;
my $rados = &$librados_connect($scfg, $storeid);
my $df = $rados->mon_command({ prefix => 'df', format => 'json' });
my ($d) = grep { $_->{name} eq $scfg->{pool} } @{$df->{pools}};
# max_avail -> max available space for data w/o replication in the pool
# bytes_used -> data w/o replication in the pool
my $free = $d->{stats}->{max_avail};
my $used = $d->{stats}->{stored} // $d->{stats}->{bytes_used};
my $total = $used + $free;
my $active = 1;
return ($total, $free, $used, $active);
}
