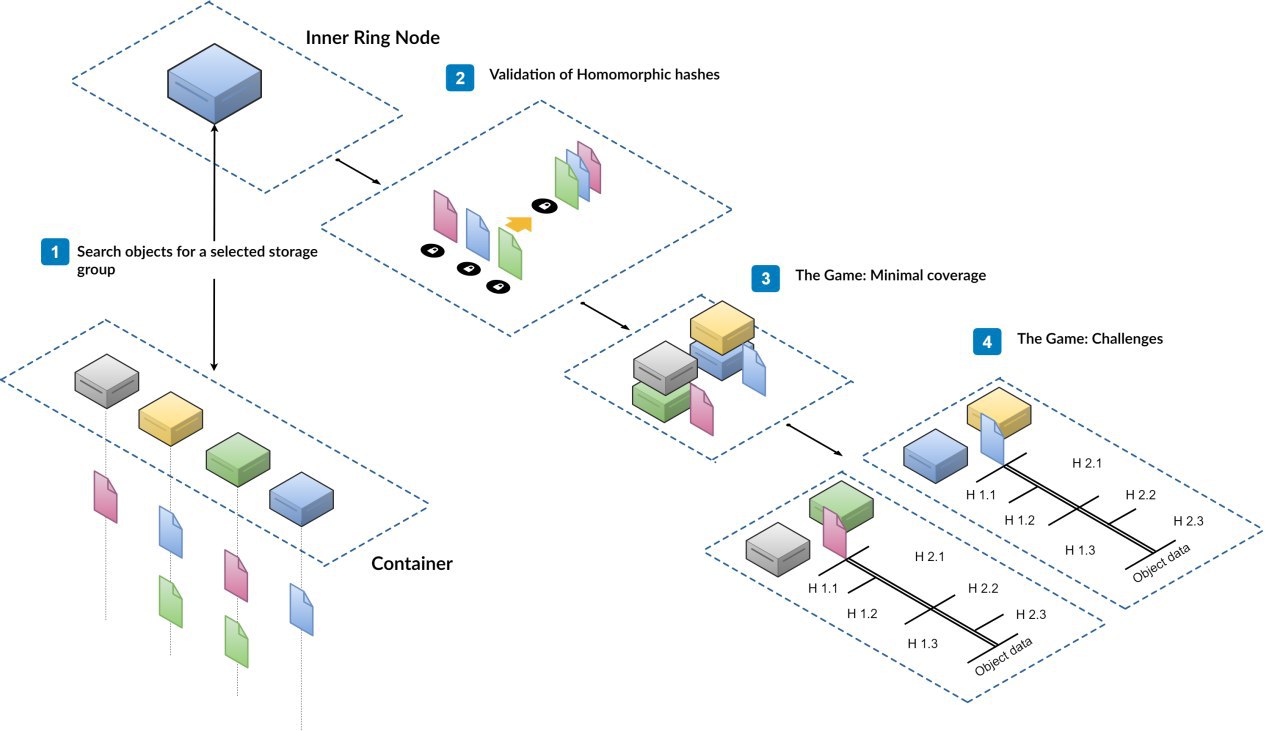
При всем этом надо учитывать что каждый узел состоит в большом количестве контейнеров и хранит еще большее кол-во групп хранения (элемент проверки). Объекты проверки и диапазоны случайны. Обман становится экономически невыгоден. Сама проверка, несмотря на длинное описание, достаточно легковесна и дешева. Реальные данные не пересылаются по сети.
Вот я воткнулся как раз в "Диапазоны выбираются случайным образом (кол-во возможных сочетаний челленджей очень велико и ограничено лишь размерами самого объекта)" - фишка в том, что меня каждый раз просят предоставить хеши от новых частей файла? типа, если файл - 1Кb в длину, меня просят предоставить три хеша от рандомных диапазонов байт? например с 12 байта по 78, с 89 по 125 и с 179 по 267? Сорри, если торможу - возможно поможет, если подскажете как выглядят несколько challenge-й для одного и того же объекта при разных рандомах? (ну и заодно пойду перечитаю про гомоморфное хеширование). В остальном модель вроде понятна...
Кстати, спасибо за подкаст - интересно1