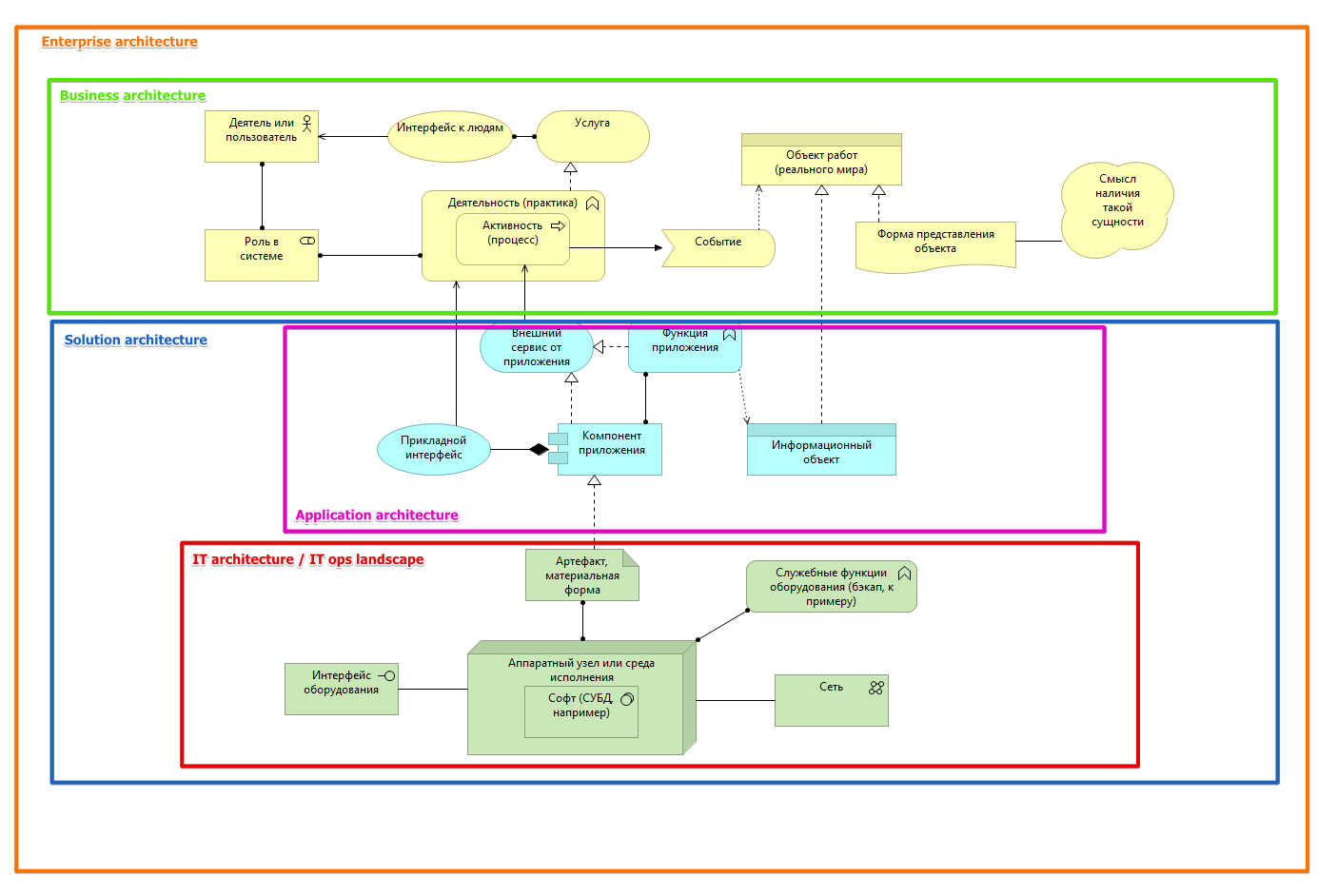
За мониторинг тележка.
Как только начал, сразу предупрежу, что на мой вкус, нет такого понятия "мониторинг", вокруг которого все сели и договорились. Соответственно, даже у нас происходят периодически холивары о том, куда необходимо следовать дальше.
Для некоторых это будет диспетчерский центр с эргономичной мебелью и экранами во всю стену. Для других — СМС на пейджер, что система испытывает проблемы. Третьему достаточно периодических картинок в чат, и всё такое.
Поэтому, ваш мониторинг, наверное, совсем не такой, как у нас. А как у нас?
Для нас это инструмент, решающий следующие задачи:
1. Обнаружение нештатного поведения системы
2. Помощь в расследовании инцидентов, когда они случились; при этом нужны данные на глубину неделя-две-месяц.
К сожалению, стабильного повторяемого опыта предотвращения (2), глядя на (1), у нас нет
Что из этого важнее? Оба важнее. Что такое нештатное поведение системы? Да хрен его знает, на самом деле. НО — мы можем зафиксироваться о поведении, когда пользователи вроде как довольны, и когда — недовольны, и интерполировать показатели, пытаясь понять, что так, а что не так.
По этой причине мы обмазались немалым количеством инструментов для:
- сбора логов
- коллекционирования логов
- анализа логов
- трассировки запросов, как синтетических, так и натурально пользовательских онлайн
- некоторые оперативные инструменты типа OEM (Oracle Enterprise Manager — знает всё-всё про состояние и процессы внутри БД).
Для трассировки и заглядывания внутрь мы используем инструменты CA Infrascope и Riverbed.
Прелесть этих инструментов — в том, что они сами подстраиваются под твоё приложение. Достаточно указать агенту, что за приложение стартовано (точнее, попросить приложение подгрузить в себя агент), и дело в шляпе. Агент проанализирует устройство приложения, разберёт его на компоненты, покажет сервисы, которые это приложение выставляет, и начнёт вести статистику по ним. Для каждого входящего запроса покажет статус, время исполнения, результат, и на какие составляющие распадается, включая обращения к внешним сервисам. Плюсы — очень удобно. Минусы — недёшево.
Для прогона синтетических транзакций используются самописные инструменты, включая мониторинг среднего (конечно же, не среднего) времени отклика системы.
Всё это даёт представление о том, каково пользователям работать с нашей системой. Онлайн-статистика постится картинками и табличками в разные чаты (телеграмм, к примеру). Это даёт возможность видеть массовые сбои ещё до того, как на них отреагирует служба поддержки. И не только прямые сбои, но и косвенные. К примеру, если отказал UI, то мы увидим уменьшение числа запросов к бизнес-операциям сервисной платформы.
Теперь про расследование инцидентов — то, что не онлайн.
Логи собираются с каждого узла. Обычно это плейн-текст. Джава, .нет, 1C, логи серверов приложений, access log на шлюзах, логи шины, har-логи с клиентских машин — всё это собирается. Собранные логи транспортируются в места хранения и складируются там. Для этого используются Flume, Greylog, Kafka и прочие. Инструментарий — разнородный. Для хранения и анализа используются тоже разные продукты. Из тех, что помню - Kibana. Важно, чтобы инструмент позволял заглянуть в прошлое, все используемые нами позволяют.
Ну и инструменты, о которых я не упомянул — OEM, разнообразные консоли управления инструментов (типа weblogic-а), консоли шины — нужны для сбора специфичных данных по запросу, в случае расследования ошибок. Это тоже часть мониторинга.
Почему такой разнобой в тулах? В случаях проблем поможет любая деталь, поэтому логи могут параллельно складироваться в несколько мест, и анализироваться разными людьми и разными инструментами.
Важно: конфигурации и инструменты мониторинга непрерывно меняются, и это нормально для нас.