Ребят, всем привет. Может сталкивался кто? Подскажите пожалуйста.
На текущий момент имеем 3 разных сервера мониторинга с версией 2.4 по ±300 узлов на каждом. Под ними БД MySQL 5.7, все в innodb per table. В среднем запись на каждом Zabbix-Server по ±1000 значений в секунду. В какой-то момент на них перестает отрабатывать housekeeper (когда база разрастается до 30-45GB на диске), точнее начинает отрабатывать все дольше и дольше, хотя чистка стоит каждый час и по 100000 записей. В итоге буквально за недели 2 происходит наполнение БД с нуля до 30-45Gb и housekeeper перестает отрабатывать. При ходится каждый раз чистить таблицы с историей, что вообще плохо. В шаблоне zabbix agent есть элемент данных agent ping, на который завязна триггер "server ${hostname} is unreachble". Так вот при отработке housekeeper все узлы начинают периодичнски загораться красным, и шлют алерты. При этом они могут погаснуть и потом опять начать загораться и снова слать алерты и так постоянно пока работает housekeeper. А он никогда почему-то никогда не может закончить свою отрабокту, даже если поставить ему удалять по 500 записей. В чем дело не понятно. Тюнинг везде на максимум, что делать не знаю.
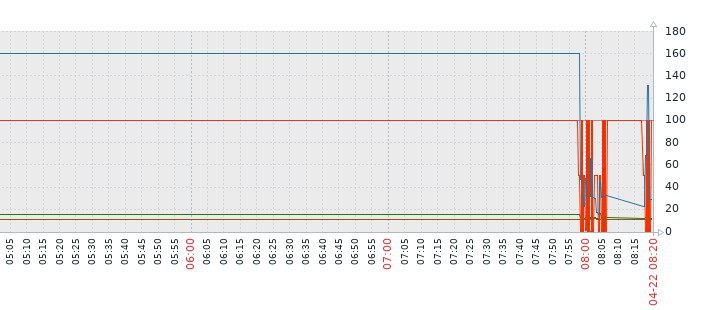
Грешили на старую версию Zabbix, решили попробовать новую для тестов. Сейчас имеем Zabbix 4.4 пустой, с БД в виде PostgreSQL на базе stolon. И сохранением истории в ElasticSearch 6.3 (3 ноды). Подключили для тестирования 30 узлов. В 100% стала нагрука "history syncer internal processes. Проблем с houskeeper нет, но периодически все узлы постоянно начинают гореть unreachble. Хотя с чего бы, если на сервере всего 30 узлов подключено..
Если убрать запись в Elasticsearch, и настроить ее в PostgreSQL, то график history syncer internal processes при 30 узлах держится где-то на 20%, что конечно лучше при 100% в ElasticSearch. Но почему так? Да и ладно бы, можно оставить запись в PostgreSQL, если с ElasticSearch нагрузка выше почему-то. Но даже на новой версии узлы все равно загораются unreacheble и шлют ложные уведомления.
Кто-нибудь сталкивался с таким? Куда копать просто не понятно. Подскажите пожалуйста.
Можно еще посмотреть в сторону оптимизации шаблонов, 3нвпс на один узел мониторинга это многовато. В 4.4 появился в препроцессинге не писать в базу если значение не менялось, полезно для всяких статусов минутных. У себя добился 0.5 нвпс на хост при 100 метриках на узел.