Кстати, приятно, что нет 👎 в прошлом посте, значит моя инициатива интересна.
Обещал начать писать - начинаю.
Пятница, поэтому пятничный пост.
Не совсем про Кафку, но тут присутствуют важные игроки из индустрии.
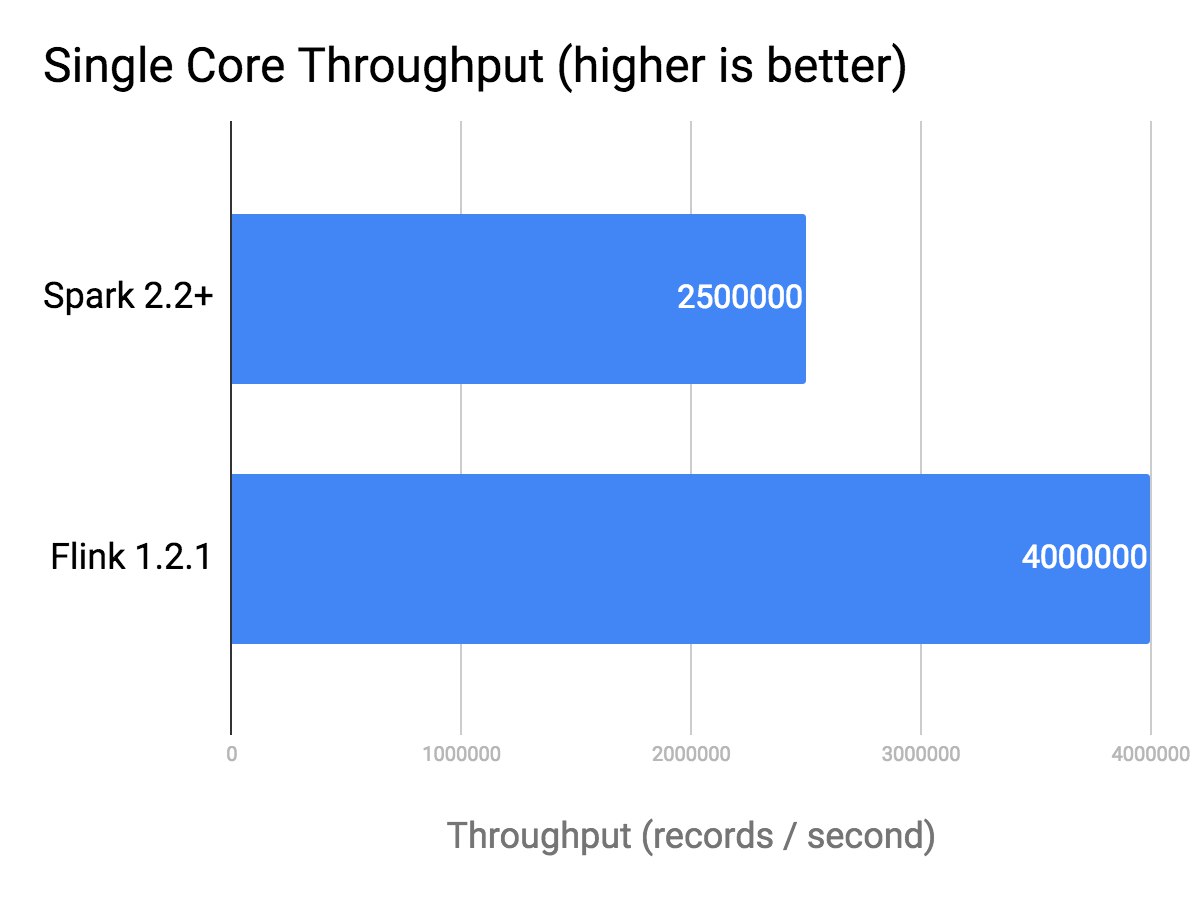
DataArtisans - ребята, которые разрабатывают Apache Flink и пытаются на нем зарабатывать денежку, написали очень занятный блог про бенчмарки.
Похоже, что не одну индустрию не обходит эта занимательная тема.
История такая, посоны из Databricks (ребята, ковыряют Spark) выложили бенчмарк, в котором Spark Streaming (сурпрайз, сурпрайз) оказался быстрее и Flink и Kafka Streams.
DataArtisans поглядели на это дело, и нашли и засучили рукова.
Оказывается, что в дата генераторе для Flink было один классический баг -
LinkedList vs Array(List?). Я не большой эксперт в scala и не могу точно сказать, что скрывается под капотом у Array, но тут на лицо O(n) vs O(1) .Там еще много чего есть. Отличное пятничное чтиво ☕
Мораль
> (я так приблизительно всегда говорю и клиентам и слушателям)
Не стоит полагаться на бенчмарки при выборе технологии, которая будет критична для вашей продакшн системы.
Проверяйте сами, условия для бенчмарков всегда можно притянуть так, чтобы победил кто надо.
Бенчмарки от вендора - это в двойне подозрительно.
Всегда проверяйте то, что вы используйте.
Берегите себя!