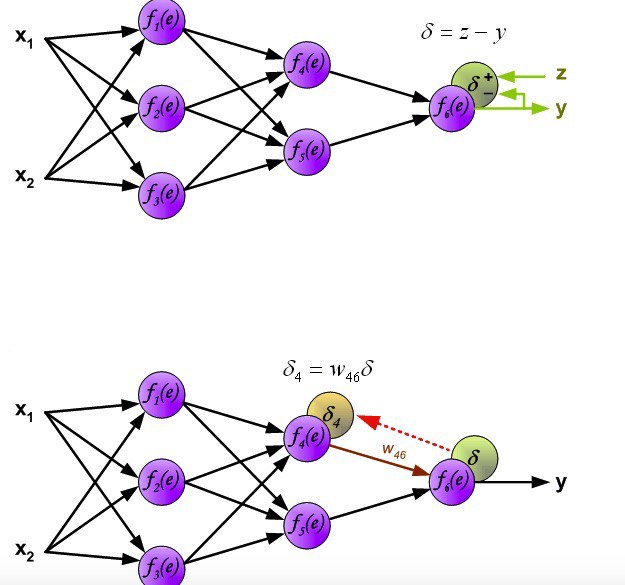
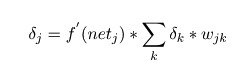Gennady Borisov
Т.е. тестовую выборку трогать нельзя, наны заполнять, совместно с тренировочной и т.д=)?
У меня скорее вопрос, тестовые данные должны оставаться сырыми, который просто в модель обученную на тренировочной выборке вставлять. Или тренировочную выборку тоже можно предобрабатывать?
Если вы имеете в виду, можно ли на тренировке так или иначе задействовать информацию из теста, то ответ такой: с точки зрения реальной жизни — нет, нельзя, это лик, если же цель получить максимальное качество на конкретном наборе тестовых данных (о чем практически все соревнования), то, конечно, можете